

Introduction
The data center is no longer just an IT facility. It is rapidly becoming a factory floor for intelligence. As organizations race to train and deploy AI models, traditional infrastructure designs are reaching their limits. This shift has introduced a new concept: AI factories. It focuses on maximizing throughput for training and inference workloads.
The arrival of NVIDIA Blackwell has accelerated this transition. Built around six revolutionary technologies, Blackwell architecture is engineered to enable AI training and real-time LLM inference for models scaling up to 10 trillion parameters. With unprecedented compute density, advanced interconnects, and rack-scale designs, it is reshaping how organizations think about AI infrastructure from the ground up.
This blog explores what AI factories are, how they differ from traditional data centers, why Blackwell matters, and what enterprises must consider when building future-ready AI computing infrastructure.
What Is an AI Factory?
An AI factory is a purpose-built computing environment optimized not for general workloads but for AI model training and inference at scale. It prioritizes GPU throughput, memory bandwidth, and the speed at which raw power converts into AI-generated outputs.
Every AI factory is built from the same foundational layers. Understanding these components helps you see why distributed GPU computing demands a completely different infrastructure model than conventional IT.
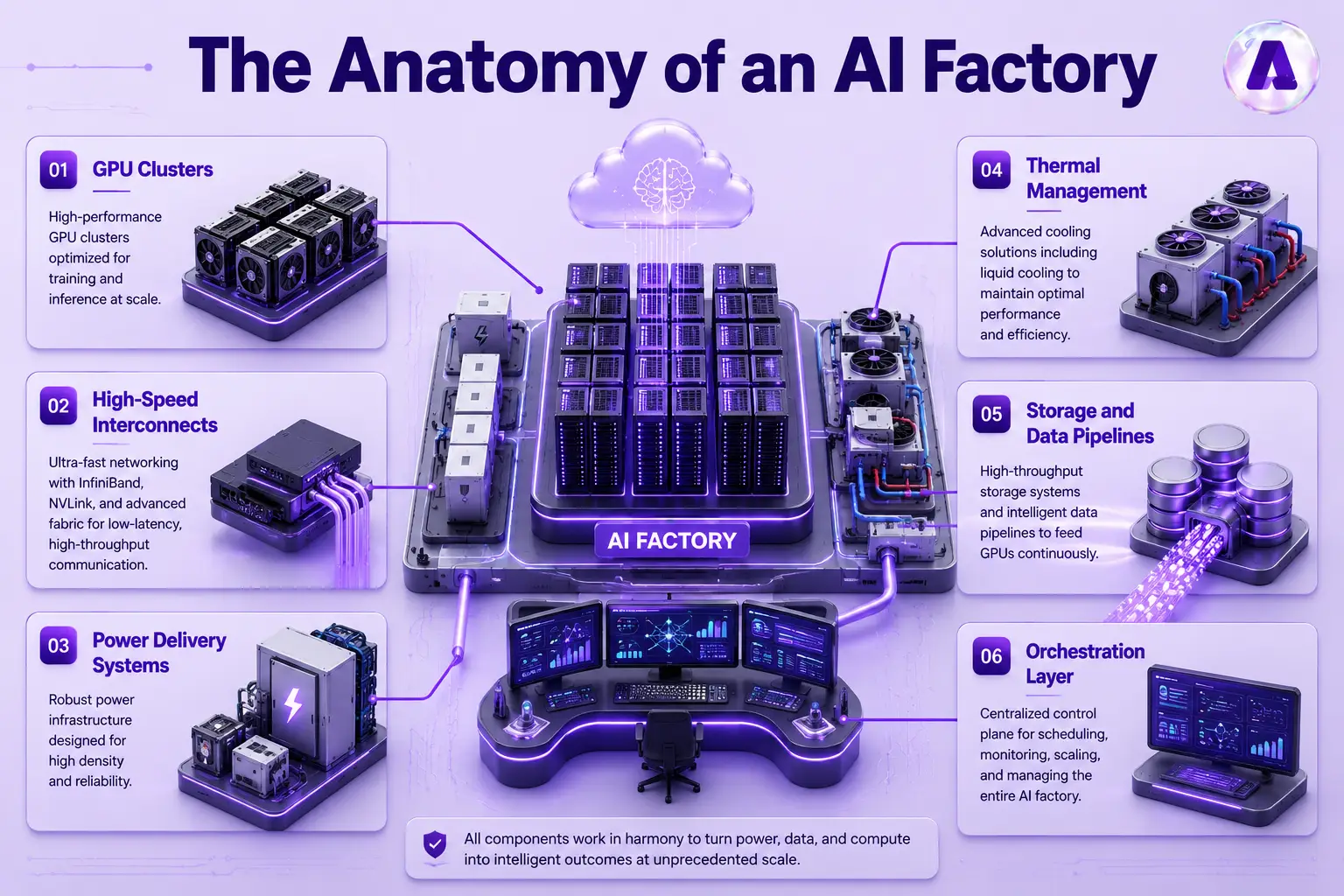
- GPU Clusters: Dense arrays of accelerated processors that handle matrix math at scale for both AI training infrastructure and inference workloads.
- High-Speed Interconnects: NVLink, InfiniBand, and PCIe fabrics that move data between GPUs fast enough to prevent compute stalls.
- Power Delivery Systems: High-density power distribution units (PDUs) designed to feed racks drawing 100 kW and above.
- Thermal Management: DLC and immersion cooling systems that remove heat at densities air cooling cannot handle.
- Storage and Data Pipelines: High-throughput storage arrays that feed training datasets to GPUs without creating I/O bottlenecks.
- Orchestration Layer: Software stacks — Kubernetes, SLURM, or NVIDIA Base Command — that schedule and manage distributed AI workloads.
AI Factory vs. Traditional Data Center
| Aspect | AI Factory | Traditional Data Center |
|---|---|---|
| Purpose | Optimized for AI model training, inference, and accelerated computing workloads | Designed for general-purpose computing, storage, databases, and enterprise apps |
| Compute Infrastructure | Large-scale GPU clusters and specialized AI accelerators | Primarily CPU-based servers with limited GPU deployment |
| Performance Metric | Measures success through model throughput, tokens processed, and AI output generation | Measures uptime, resource utilization, and app performance |
| Power Density | 50-150+kW per rack | 5-15 kW/rack |
| Networking | High-speed networking using InfiniBand, NVLink, and advanced GPU interconnects | Standard Ethernet-based networking for general workloads |
| Cooling Strategy | Direct liquid cooling (DLC) and immersion cooling increasingly common | Predominantly air-cooled infrastructure |
| Architecture Design | Built around distributed GPU computing and high-performance AI clusters | Built around individual servers, virtualization, and storage systems |
| Workload Focus | LLM training, GenAI, machine learning, and AI inference | Business apps, web hosting, databases, ERP, and file storage |
| Scalability Model | Scales GPU clusters across racks and AI pods | Scales through additional servers and virtual machines |
| Business Outcome | Converts power and data into AI models, predictions, and intelligence | Delivers IT services, app hosting, and data management |
NVIDIA Blackwell Architecture: The Engine Behind AI Factories
To understand why AI factories are evolving so rapidly, you first need to look at the technology driving this transformation: NVIDIA Blackwell, a GPU architecture designed specifically for large-scale AI training and inference.
What Is NVIDIA Blackwell Architecture?
Blackwell is NVIDIA’s fifth-generation GPU architecture, announced in March 2024 and now forming the backbone of next-generation AI data centers worldwide. Named after mathematician David Harold Blackwell, this architecture is built from the ground up for trillion-parameter AI models.

The flagship B200 GPU packs 208 billion transistors across a dual-die design connected by a 10 TB/s chip-to-chip interconnect, which is the highest transistor count in NVIDIA’s history. It introduces a second-generation Transformer Engine with FP4 precision support, which doubles throughput compared to the previous Hopper generation for LLM workloads. Blackwell also supports PCIe Gen 6 and NVLink 5, which clocks at 1.8 TB/s of GPU-to-GPU bandwidth.
According to NVIDIA, the B200 delivers up to 30x less energy per inference operation compared to the H100. That figure alone explains why enterprises and cloud providers are moving to Blackwell-based AI infrastructure as fast as supply allows.
Grace Blackwell Superchip
The Grace Blackwell Superchip (GB200) combines NVIDIA’s Grace CPU with a Blackwell B200 GPU on a single package connected by a 900 GB/s chip-to-chip NVLink interface. This tight CPU-GPU integration removes the PCIe bandwidth ceiling that constrained previous GPU server designs, making it ideal for large language model training infrastructure where data movement between host and accelerator matters enormously.

GB200 NVL72
The GB200 NVL72 takes this further. It is a rack-scale system housing 36 Grace CPUs and 72 Blackwell GPUs in a single connected unit using the NVLink Switch fabric. This creates what NVIDIA calls a single GPU abstraction — 72 physical GPUs that behave as one logical accelerator with 8 petaflops of AI compute and 13.5 TB of fast memory. For distributed GPU computing at scale, this changes the architecture conversation from ‘how many servers’ to ‘how many racks.’

How Blackwell Changes Data Center Architecture?
Blackwell forces a rethink of how data centers are designed at every layer. The shift is from server-level thinking to rack-level and pod-level architecture.
Where a Hopper-generation deployment might treat each DGX node as an independent unit networked together, a Blackwell deployment treats the entire GB200 NVL72 rack as the minimum computing unit. This affects floor planning, power distribution, and cooling design.
Data centers built for Blackwell also require rethinking cable management. The NVLink Switch fabric inside a GB200 NVL72 rack replaces the external spine-leaf networking that connected individual GPUs in older clusters.
Building the Infrastructure: What Goes Inside an AI Factory
An AI factory performs as a unified system only when its networking, cooling, and power infrastructure are designed to support large-scale AI workloads. Let’s begin with the networking technologies that make high-performance GPU communication possible.
High-Speed Networking
Networking is where AI factories diverge most visibly from conventional data centers. In a traditional environment, 10 or 25 Gbps Ethernet links between servers are more than adequate. In an AI factory, a single GPU-to-GPU communication delay of a few microseconds can stall the entire training job across thousands of accelerators.
- InfiniBand Networking: Specifically, NVIDIA’s Quantum-2 and the upcoming Quantum-3 platforms provide the GPU-to-GPU communication fabric between racks and pods. Current-generation HDR and NDR InfiniBand deliver 200–400 Gbps per port with sub-microsecond latency, which is what distributed AI training requires at scale.
- NVLink Switch fabric: Inside a GB200 NVL72 rack, NVLink handles intra-rack GPU interconnects at 1.8 TB/s total bandwidth — orders of magnitude beyond what any external network switch can deliver.
This two-tier networking model (NVLink inside the rack, InfiniBand between racks) is the standard architecture for high-performance AI clusters today.
Cooling Systems for AI Factories
Air cooling: The default thermal management approach for most data centers. It hits a physical wall when rack densities cross 40–50 kW. At 120 kW per rack, forced air simply cannot remove heat fast enough without creating thermal runaway conditions.
Direct liquid cooling (DLC): DLC runs chilled water through cold plates mounted directly on GPUs, CPUs, and memory modules. It can remove 50–70% more heat per unit volume than air, making it the dominant approach for AI factory thermal management.
Immersion cooling: It is the submerging servers in dielectric fluid handling even higher densities and is gaining ground in purpose-built hyperscale AI data center builds.
NVIDIA ships the GB200 NVL72 as a liquid-cooled unit by design. There is no air-cooled variant. This signals the industry direction: any operator planning AI computing infrastructure around Blackwell needs to have liquid cooling infrastructure in place before the first rack arrives on the floor.
According to Uptime Institute, liquid cooling adoption in data centers reached 20% in 2023 and is projected to exceed 50% by 2027, driven almost entirely by AI workload density requirements.
AI Factory Power Requirements
Power is where AI factory planning gets most challenging. According to Goldman Sachs Research, AI data center power demand is expected to grow 165% by 2030, pushing energy infrastructure investment to the forefront of AI deployment planning. A hyperscale AI data center cluster of 100,000 Blackwell GPUs can consume between 500 MW and 1 GW of electrical power. Even a modest enterprise AI factory at 500–1,000 GPU scale draws 5–10 MW, enough to require dedicated utility substations.
This brings up the concept of grid-to-token efficiency, a metric that measures how much electrical power from the grid results in how many AI output tokens. It captures the full chain from utility power to transformer forward pass, including cooling overhead, power conversion losses, and GPU utilization rates. Improving grid-to-token efficiency is the central engineering challenge for AI factory operators.
Who Is Building AI Factories and Why?
With these infrastructure challenges in mind, it is equally important to examine who is investing in AI factories and the strategic motivations driving these large-scale deployments.
Hyperscalers and Cloud Providers
Microsoft, Google, Amazon, and Meta are the most visible builders of hyperscale AI data centers. Their motivation is straightforward: every AI product they ship — from Copilot to Gemini to Alexa — depends on inference infrastructure that must serve hundreds of millions of requests per day at millisecond latency.
Microsoft announced plans to invest $80 billion in AI data center infrastructure in fiscal year 2025 alone. Google’s capital expenditure for 2024 exceeded $52 billion, with the majority directed at AI computing infrastructure. These are wholesale reinventions of data center strategy, driven by the economics of AI as a product layer.
For cloud providers, AI factories also represent a revenue product. AWS, Azure, and Google Cloud all offer GPU cluster access at premium per-hour rates. The more AI infrastructure they build, the more AI compute they can sell to enterprises that cannot justify building their own.
Sovereign AI Factories
One of the more significant geopolitical developments in AI infrastructure is the rise of the sovereign AI factory. It is the national-scale computing installations that give governments direct control over AI capability, training data, and model outputs.
The nations that depend entirely on foreign cloud providers for AI compute face both strategic risk and economic leakage. A sovereign AI factory gives countries the ability to train models on national data under national privacy law, without routing sensitive information through third-party infrastructure.
The UAE has invested heavily in its Falcon AI program, with AI data center builds that position Abu Dhabi as a regional AI hub. India’s IndiaAI mission targets 10,000 GPU capacity under direct government procurement. NVIDIA has become a central partner in many of these programs, with Blackwell serving as the default GPU architecture for sovereign AI factory deployments.
Enterprise AI Deployment
Beyond hyperscalers and governments, mid-market and large enterprises are increasingly building private AI infrastructure rather than relying solely on cloud GPU rental.
- Healthcare organizations are deploying AI factories to train diagnostic models on patient data that cannot leave on-premises environments.
- Financial institutions need AI inference infrastructure with deterministic latency guarantees that public clouds cannot always provide.
- Manufacturers are running predictive maintenance and quality control AI on edge AI factory nodes co-located with production lines.
Enterprise AI deployment at this level no longer means spinning up a few virtual machines. It means planning GPU clusters, interconnect topology, power capacity, and cooling. Each layer must be sized correctly from the start, because retrofitting an undersized power infrastructure or swapping out an incompatible cooling system after deployment costs far more than getting the architecture right upfront.
Rather than handing enterprises a hardware catalog and stepping back, strategic vendors like Aptly Tech can help you start with your actual workloads. From there, it works backward to the right infrastructure configuration, so your capital goes toward compute that performs rather than capacity that sits idle.
Aptly Technology — Accelerating Your AI Factory Journey
Building an AI factory involves decisions that span multiple disciplines simultaneously. Most enterprise IT teams are expert in some of these domains but rarely all of them. Also, the margin for misalignment between layers is low when racks cost hundreds of thousands of dollars.
Aptly Technology works with organizations at every stage of the AI factory lifecycle. Whether you are evaluating the business case for on-premises AI computing infrastructure, selecting between GB200 NVL72 configurations, or optimizing an existing GPU cluster for better utilization, Aptly brings the technical depth and vendor relationships to close the gap between ambition and execution.

The platform also provides architecture consulting that starts with your actual workloads — LLM fine-tuning, inference serving, computer vision pipelines. This avoids the common mistake of over-buying GPU capacity while under-investing in the networking and cooling that determines whether those GPUs ever reach full utilization.
From concept to commissioning, Aptly covers the full delivery chain so your team can focus on building the models, not the infrastructure underneath them.
The Future of AI Factories
NVIDIA has publicly outlined its roadmap beyond Blackwell. The Rubin GPU architecture is slated for release around 2026, continuing the company’s two-year cadence of major GPU generations.

Rubin is expected to build on Blackwell’s rack-scale design philosophy while introducing next-generation HBM4 memory, higher NVLink bandwidth, and further improvements to the Transformer Engine for both training and inference.
For infrastructure planners, the Rubin roadmap reinforces an important point: AI factory design should be modular and upgrade-friendly. Organizations that design their power, cooling, and networking infrastructure to handle Blackwell today — but with headroom for Rubin’s anticipated power density increase — will avoid costly retrofits when the next generation arrives.
Conclusion
AI factories represent the new baseline for organizations serious about building, deploying, and scaling AI. The NVIDIA Blackwell architecture provides the compute foundation that makes rack-scale AI a practical reality rather than a theoretical goal.
The decisions you make about GPU clusters, power density, liquid cooling, and high-speed networking in the next 12–24 months will define your organization’s AI capability for years ahead. Aptly Technology is ready to help you design and build your AI factory with the right hardware, the right architecture, and the right support.
FAQs
Q1. Explain AI factories in simple terms.
An AI factory is a specialized data center designed to do one thing exceptionally well: process massive amounts of data to train and run AI models. It is filled with GPU clusters, ultra-fast networking, and purpose-built cooling, all tuned to maximize the speed at which raw compute power turns into AI outputs.
Q2. How does NVIDIA Blackwell transform data centers?
Blackwell shifts the fundamental unit of AI computing from the individual server to the rack. The GB200 NVL72 system treats 72 GPUs as a single logical accelerator. It delivers up to 30x better inference energy efficiency compared to the H100 generation.
Q3. What components make up an AI factory?
A complete AI factory includes GPU clusters, high-speed GPU interconnects, power delivery systems rated for 100+ kW per rack, DLC/immersion cooling, high-throughput storage for training datasets, and software orchestration platforms for scheduling distributed AI workloads. Each layer must be designed in coordination.
Q4. What is the cost of building an AI factory?
Costs vary enormously by scale.
- A small enterprise AI factory at 500–1,000 GPU capacity can run $20–50 million.
- A hyperscale AI data center at 100,000+ GPU capacity can exceed $10 billion when facility construction, power infrastructure, and long-term operational costs are included.
- The hardware cost per Blackwell GPU is in the $30,000–40,000 range, and that is before accounting for the supporting infrastructure that typically equals or exceeds the raw hardware cost.
Q5. How are AI factories optimized for generative AI?
Generative AI workloads are hungry for memory bandwidth and require moving enormous tensors between compute units with minimal delay. AI factories address this through high-bandwidth memory, NVLink Switch fabrics, and the Transformer Engine. The result is infrastructure purpose-built for the matrix operations that underpin every generative AI output.
Q6. Which industries benefit most from AI factories?
Healthcare organizations, financial services firms, manufacturing companies, and research institutions.




