

Why GPU Data Centers Are the Infrastructure Investment of the Decade
The data center industry is undergoing the most significant architectural shift in its history. Traditional CPU-based data centers, built to store and process files, are giving way to GPU data centers designed to produce intelligence at scale. At Computex 2026, NVIDIA CEO Jensen Huang made the shift explicit: “Your data center used to be a data center for files. It’s now a factory for tokens.”
That reframing matters for every CXO, investor, and infrastructure decision-maker reading this. GPU data centers are not a technology upgrade. They are a new category of productive asset. They generate AI outputs: predictions, content, decisions, and models. The question is no longer whether to invest. It is how to invest intelligently, at the right scale, in the right deployment model.
The global GPU data center market grew from $30.44 billion in 2025 to $36.88 billion in 2026 and is projected to reach $124.19 billion by 2032, expanding at a 22.24% compound annual growth rate. Separate analysis from Precedence Research projects the market reaching $226.87 billion by 2035 at a 26.41% CAGR. Every major forecast points in the same direction. This market is growing faster than almost every other infrastructure sector, and the underlying demand drivers are structural, not cyclical.
The GPU Data Center Market Opportunity in 2026
The numbers behind this market are not projections based on optimistic assumptions. They reflect committed capital already flowing into GPU infrastructure at every level: enterprise, hyperscaler, and national government.
Global AI capital expenditure in 2026 is projected at $480 billion, with sovereign AI and enterprise AI accounting for 17% of that total. Global spending on sovereign AI infrastructure alone has surpassed $100 billion in 2026, with governments pledging over $1.5 trillion in cumulative AI infrastructure commitments through end of year 2026. Governments are treating GPU clusters as critical national infrastructure, equivalent in strategic importance to electrical grids and telecommunications networks.
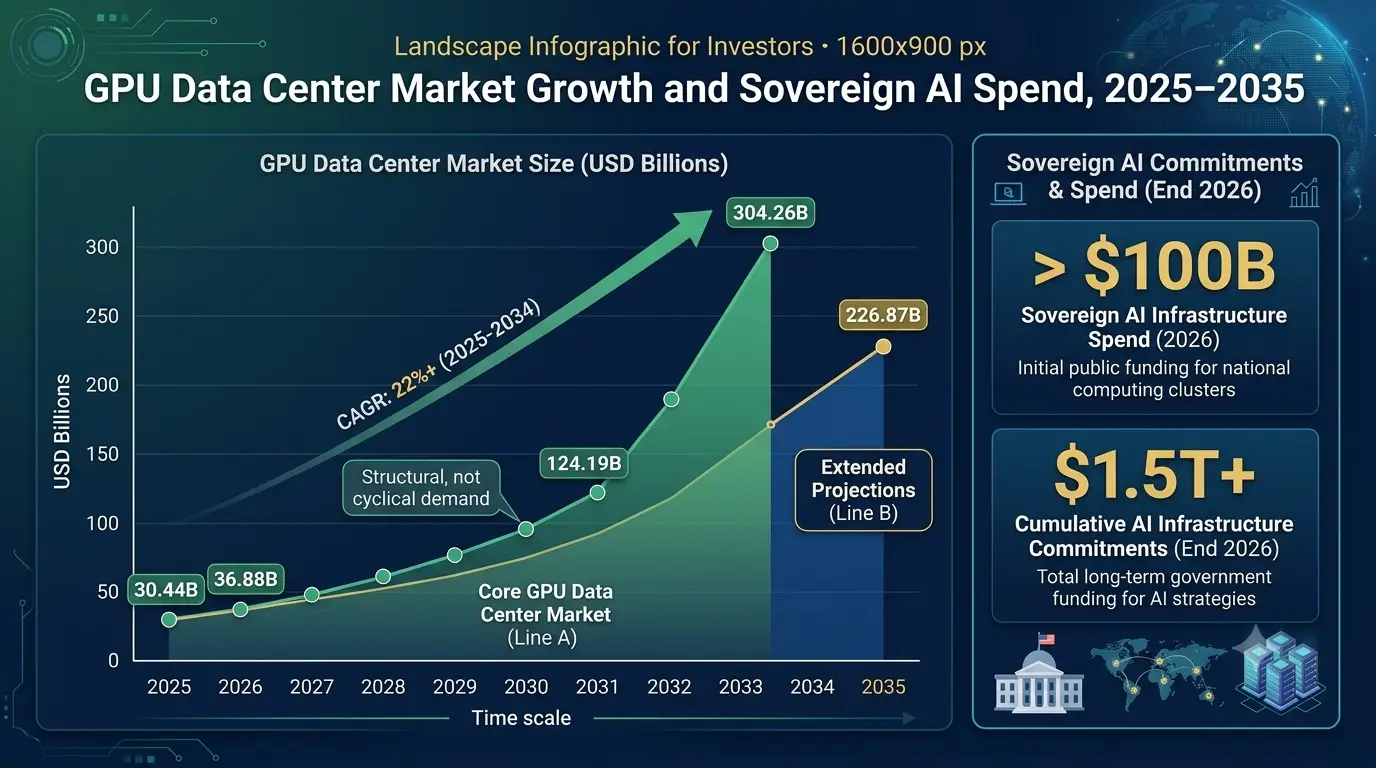
GPU data centers Market Growth & AI Spend
For business investors and enterprise AI infrastructure leaders, this sovereign wave creates a structural floor under GPU data center demand. Countries that do not build AI infrastructure cede control over AI models, AI-generated data, and AI decision-making to foreign actors. That political reality is driving investment decisions that operate on decade-long timelines, not quarterly earnings cycles.
Where GPU Data Center Demand Comes From:
- Generative AI workloads: Large language model training and inference dominate GPU compute demand in 2026, with AI contributing 49.87% of GPU-as-a-Service market share.
- Accelerated computing for HPC: Scientific simulation, drug discovery, genomics, and climate modeling all run on GPU-accelerated high-performance computing infrastructure.
- Enterprise AI infrastructure build-outs: Every enterprise deploying AI at scale eventually faces the build vs. buy vs. colo decision for GPU infrastructure.
- Sovereign AI infrastructure programs: National GPU programs in the EU, UAE, Saudi Arabia, India, Japan, Canada, and the UK are injecting billions directly into GPU data center construction.
- GPU-as-a-Service (GPUaaS): The GPUaaS market reached $7.38 billion in 2026 and grows at a 28.73% CAGR to reach $26.09 billion by 2031, creating revenue streams for colocation operators and GPU fleet owners.
What is the ROI of investing in GPU Infrastructure?
ROI in GPU data centers comes from multiple directions. Speed, cost efficiency, revenue enablement, and strategic positioning all contribute. The specific numbers depend on deployment model, workload profile, and utilization rate.
ROI From Performance: Speed as a Business Multiplier
GPU-accelerated AI infrastructure delivers up to 10x faster AI workload processing compared to CPU-equivalent setups. That speed advantage is not academic. When your team trains a model in two days instead of three weeks, you ship faster, iterate more, and reach production before competitors. McKinsey research confirms that GPU acceleration compresses machine learning cycle times by five to 50 times, creating compounding competitive advantages in every AI-dependent product line.
NVIDIA’s State of AI 2026 report documents a 20% increase in throughput on initial GPU data center deployments, with 10 to 15% reductions in capital expenditure through GPU-driven design validation. These are measurable, auditable business outcomes. Not estimates.
ROI From Cost Efficiency: Cloud vs. Colocation vs. On-Premise
The single most important ROI lever for enterprise AI infrastructure is the deployment model choice. A typical enterprise AI inference deployment running 8 NVIDIA H100 GPUs at 70% utilization on AWS costs $480,000 to $600,000 annually. The same workload in dedicated GPU colocation infrastructure costs $180,000 to $280,000 annually, a saving of up to $420,000 per year on a single eight-GPU deployment.
The break-even math is clear. At sustained utilization above 70%, on-premise or colocation GPU infrastructure runs at 40 to 60% of equivalent cloud cost. The 18-month TCO threshold: if your GPU utilization will exceed 65% consistently, dedicated infrastructure wins on cost. Below 35% sustained utilization, cloud flexibility and zero capital outlay make more economic sense.
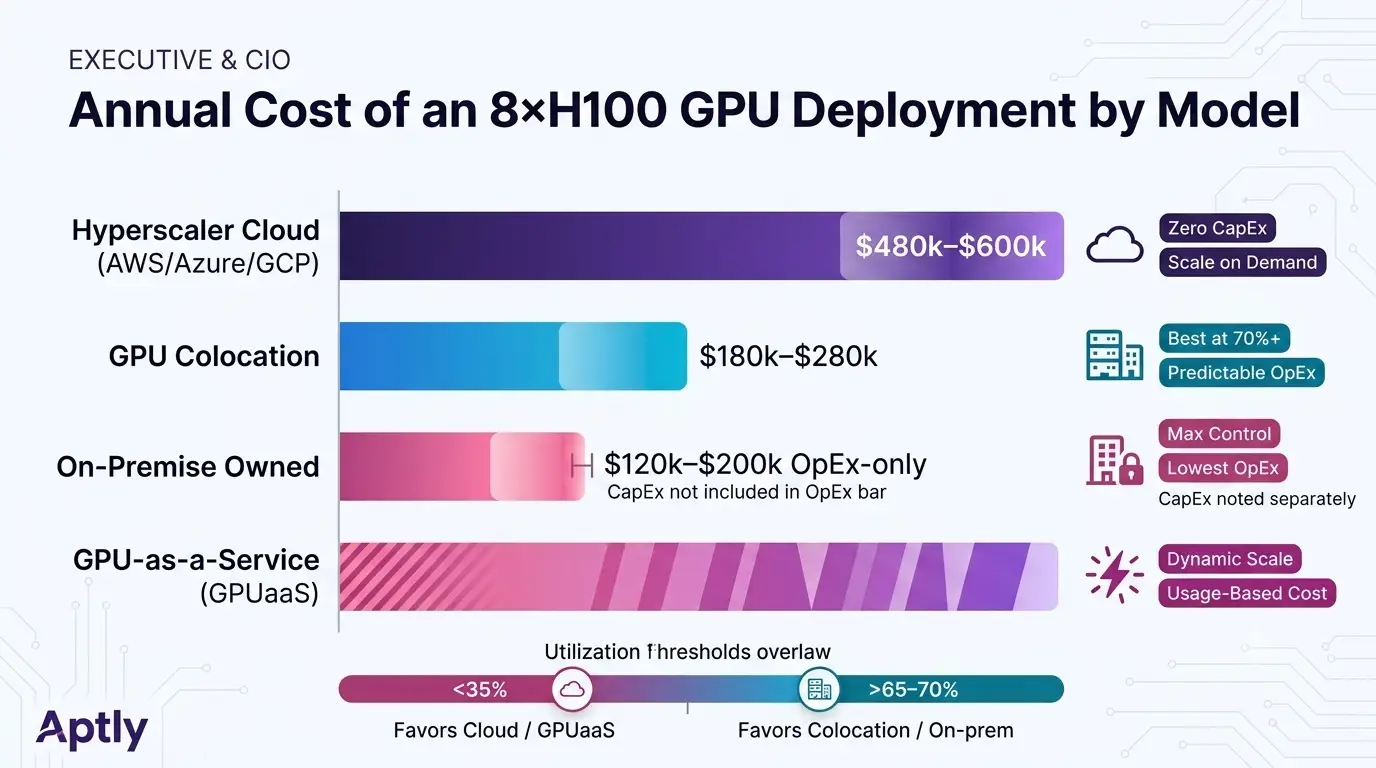
Key cost benchmark: A mid-market AI inference deployment running 4 racks at 30 kW per rack in dedicated GPU colocation costs approximately $28,000 to $39,000 per month including space, power, cooling, and amortized hardware over a 4-year refresh cycle. Equivalent AWS compute runs $480,000 to $600,000 per year.
Deloitte research shows organizations achieve 60 to 70% of cloud costs with on-premise GPU infrastructure at scale. That differential compounds significantly across multi-year investment horizons. A 1,000-GPU on-premise deployment running at 85% utilization in a secondary market typically runs at 40 to 60% of equivalent cloud cost after accounting for all non-compute costs.
ROI From Hardware: Five-Year TCO Analysis
A five-year TCO analysis of GPU hardware shows NVIDIA achieving 61.4% ROI, AMD at 68.4%, and Intel at 57.1% across full cost accounting including hardware, software, power, and maintenance. These figures assume sustained utilization rates consistent with production AI workloads, not theoretical peaks.
Prefabricated modular GPU data centers further improve capital efficiency. A 2 MW AI data center built with prefabricated modular methods costs approximately $8 million and deploys in 12 months, versus $14 million and 30 months using traditional construction. The six months of idle GPU time avoided in the faster build scenario saves $4 to $14 million in opportunity cost alone.
| Deployment Model | Annual Cost (8xH100 GPUs) | Capital Required | Best For |
|---|---|---|---|
| Hyperscaler Cloud (AWS/Azure/GCP) | $480,000 to $600,000 | Zero | Under 35% utilization, variable workloads |
| GPU Colocation | $180,000 to $280,000 | GPU hardware only | 70%+ utilization, production AI workloads |
| On-Premise Owned | $120,000 to $200,000 (OpEx only) | Full GPU + facility CapEx | 85%+ utilization, regulated data, long-term |
| GPU-as-a-Service (GPUaaS) | Variable by usage | Zero | Burst workloads, experimentation, startups |
Which Industries Benefit the Most from GPU Data Centers and their ROI?
GPU data centers serve every industry that runs AI at scale. But return on investment varies by application type, data volume, and regulatory context. Here are the industries where GPU infrastructure delivers the clearest financial case.
| Industry | Primary GPU Use Cases | Key Benefit | ROI Driver |
|---|---|---|---|
| Financial Services | Fraud detection, algorithmic trading, risk modeling | Sub-100ms inference at scale | Revenue protection, loss reduction |
| Healthcare and Life Sciences | Drug discovery, medical imaging, genomics | Model training on protein structures, diagnostic AI | Faster R&D cycles, lower trial costs |
| Manufacturing | Predictive maintenance, quality inspection, digital twins | Real-time defect detection, simulation | Reduced downtime, yield improvement |
| Autonomous Vehicles | Perception model training, simulation | Continuous GPU compute for iterative training | Development velocity, safety validation |
| Media & Entertainment | Generative AI content, rendering, VFX | GPU acceleration for rendering pipelines | Production cost reduction, creative speed |
| Retail & E-commerce | Recommendation engines, demand forecasting | Personalization at user scale | Revenue uplift, inventory optimization |
| Government & Defense | Sovereign AI programs, intelligence, simulation | Data residency, classified compute | National security, strategic autonomy |
| Energy & Utilities | Grid optimization, predictive failure, exploration | Large-scale simulation on HPC clusters | Operational efficiency, risk reduction |

Banking, financial services, and insurance post 28.6% annual growth in GPU infrastructure adoption driven by low-latency fraud detection. Healthcare and life sciences grow at 28.9% driven by imaging analytics and protein-folding simulations. Both sectors operate under strict data-protection requirements that favor GPU colocation over public cloud for sensitive workloads.
From Data Centers to AI Factories: The Strategic Redefinition
The most important conceptual shift in GPU data center investment is the AI factory model. At GTC 2026, Jensen Huang articulated the definitive framing: future data centers are not places to store and process data. They are AI factories, and their product is tokens. Every AI factory is constrained by power. A 1-gigawatt factory cannot become a 2-gigawatt factory. So the key metric is tokens produced per watt.
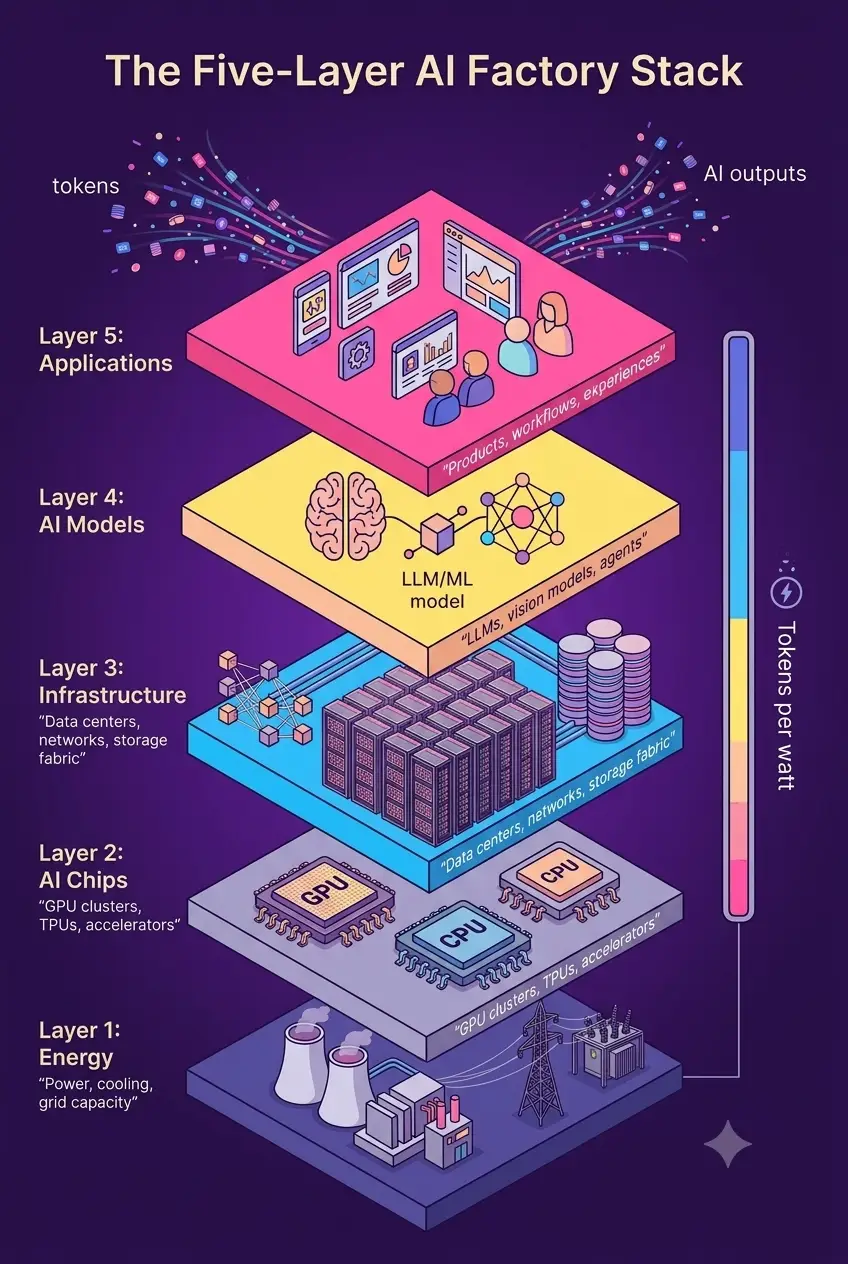
This framing changes the investment calculus entirely. An AI factory is productive capital, not passive infrastructure. It generates revenue through the intelligence it produces. NVIDIA launched Dynamo, an operating system specifically for AI factories, and the DSX platform, a digital twin blueprint for designing and operating AI factories from mechanical simulation to power grid optimization.
NVIDIA’s five-layer AI factory stack consists of energy (power), AI chips (GPUs and CPUs), infrastructure (data centers, networks, storage), AI models, and applications. Investors and CXOs who understand this stack recognize that GPU data center investment is not a single line item. It is the foundation of an integrated AI production system.
For power supply company CXOs, the AI factory model represents the most significant new demand driver for electricity infrastructure in a generation. A single 1-gigawatt AI factory requires sustained power at a scale comparable to a small city, and the pipeline of planned AI factory builds globally means power infrastructure investment correlates directly with GPU data center construction schedules.
How to Build or Access GPU Data Center Capacity: A Decision Framework for Enterprises
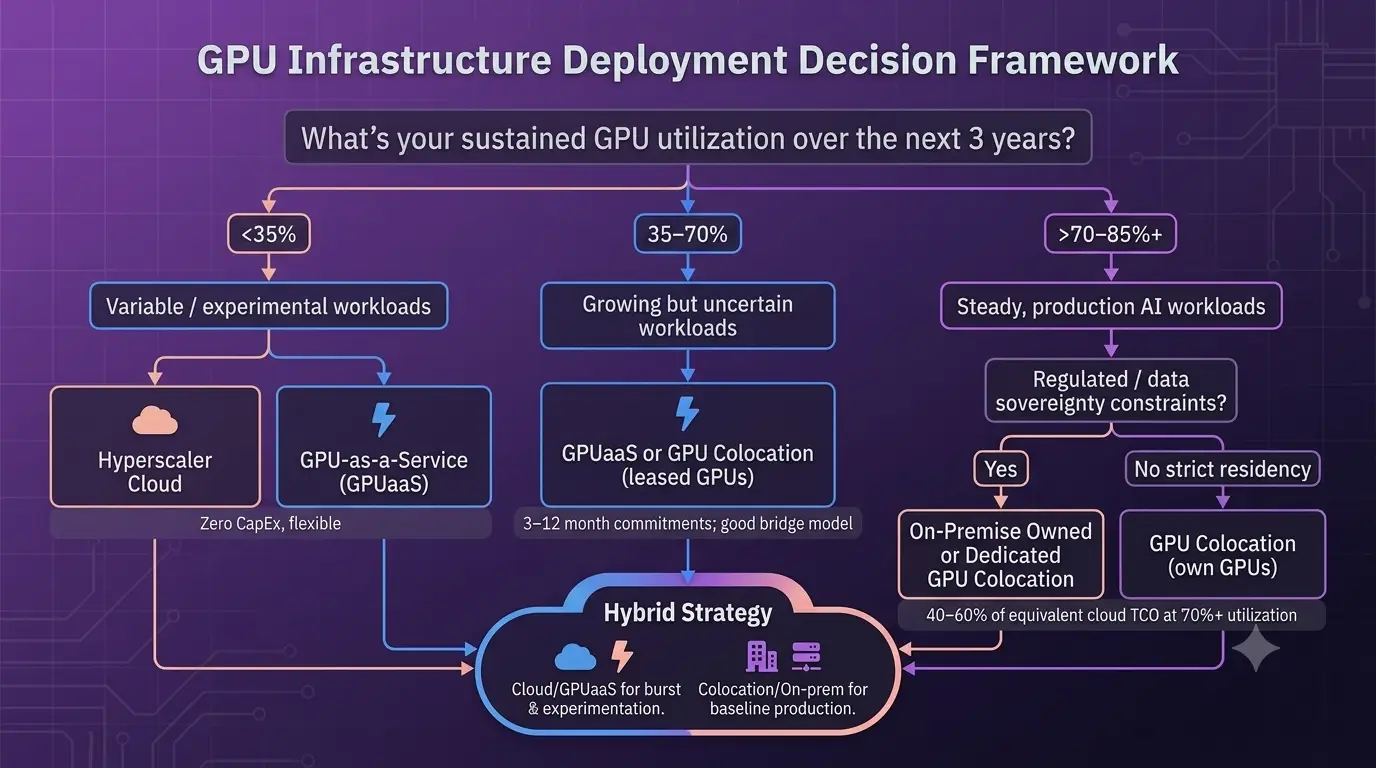
Building a GPU data center from scratch is not the right answer for most enterprises. The decision framework depends on your workload volume, utilization rate, capital availability, data sovereignty requirements, and timeline.
How Much Does It Cost to Build a GPU Data Center?
Build costs vary significantly by scale, location, and GPU density. A prefabricated 2 MW AI data center costs approximately $8 million and deploys in 12 months. A traditionally constructed equivalent costs approximately $14 million and takes 30 months. At the hyperscale end, facilities requiring hundreds of megawatts represent multi-billion dollar capital programs. GPU hardware itself dominates total build cost. A server rack running eight NVIDIA H100 GPUs carries hardware costs of $200,000 to $400,000 per rack before facility, power, cooling, and networking are added.
GPU Leasing vs. Ownership: The Enterprise Decision
GPU leasing provides access to AI infrastructure without capital commitment. GPU colocation with leased hardware at tier-2 market sites runs approximately $3.10 per GPU-hour all-in, with 12-month lock-ins instead of the four-year commitments required for owned infrastructure. For enterprises with workloads below 65% sustained utilization, leasing or cloud access typically wins on total cost. For production-grade AI workloads running continuously above 70% utilization, ownership or colocation with purchased hardware delivers superior three-year economics.
Deployment Options Compared
- Build owned GPU data center: Maximum control, lowest long-term per-unit cost at scale. Requires significant capital, 12 to 30-month build timeline, and internal operations capability.
- GPU colocation: CIOs’ preferred model in 2026 for production AI workloads. You bring the GPUs; the facility provides power, cooling, and connectivity. Combines cost efficiency with compliance control.
- GPU-as-a-Service (GPUaaS): Zero capital, maximum flexibility. Best for experimentation, burst workloads, and organizations in early AI deployment stages.
- Hybrid approach: Own or colocate GPU clusters for baseline production workloads. Use cloud for burst capacity and geographic redundancy. Most enterprise AI infrastructure leaders operate a hybrid model by 2026.
What Are the Challenges of Deploying GPU Clusters at Enterprise Scale?
GPU data center investment delivers strong returns, but the deployment path has real challenges that investors and enterprise leaders need to plan around.
- Power constraints: Colocation vacancy for AI-grade facilities sits at 1.4% globally. High-density power availability is the primary site selection bottleneck, and new power connections to existing facilities routinely take 18 to 36 months to commission.
- GPU supply and lead times: NVIDIA GPU allocation remains constrained for the largest configurations. Enterprise buyers without existing relationships or commitments face 6 to 12-month lead times for large GPU cluster orders.
- Cooling infrastructure: Traditional air cooling cannot handle GPU rack densities above 30 to 40 kW. Liquid cooling, direct-to-chip systems, or immersion cooling must be designed into the facility from day one.
- Operational expertise: Running GPU clusters at scale requires specialized talent in GPU infrastructure management, AI workload optimization, and network fabric configuration. This expertise is scarce and expensive.
- AI workload optimization: Under-utilized GPU infrastructure is expensive GPU infrastructure. Achieving the 70 to 85% sustained utilization that justifies ownership economics requires active workload management, scheduling discipline, and AI operational efficiency programs.
How Aptly Technology Addresses These Challenges
Aptly Technology is the only Microsoft-trusted supplier authorized to build and support third-party hyperscale datacenters worldwide, and it brings that same execution depth directly to enterprise GPU cluster deployments. Through its GPU Datacenter Buildout and Support service, Aptly handles full-spectrum lifecycle management: design validation against your AI workload roadmap, power and thermal zoning assessment, InfiniBand and RoCE fabric deployment, and 24×7 white-glove operations from Global Operations Centers across North America, Europe, and Asia.
For enterprises struggling with utilization economics, Aptly’s AI Workload Deployment and Optimization service fine-tunes GPU scheduling, automates CI/CD pipelines, and drives the 70 to 85% sustained utilization rates that justify GPU infrastructure investment. With direct partnerships with NVIDIA and Supermicro, pre-validated integrated rack solutions, and tens of thousands of GPU nodes delivered across Azure regions, Aptly removes the operational expertise gap that stalls most enterprise GPU programs before they reach production scale.
The Future of GPU Data Centers: Growth Outlook Through 2035
The long-term investment thesis for GPU data centers rests on four structural demand drivers that are independent of short-term AI market cycles.
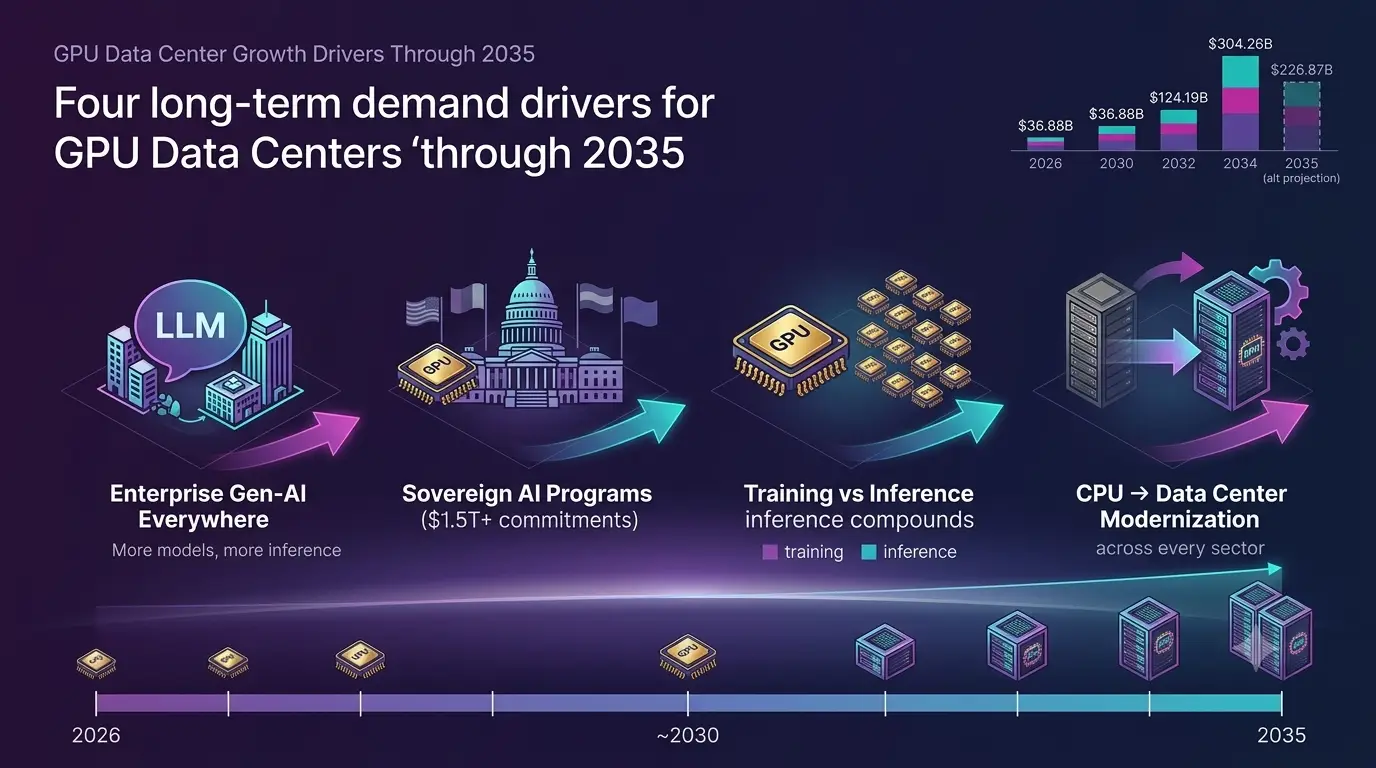
Generative AI Infrastructure at Enterprise Scale
Every major enterprise deploying generative AI at scale will need dedicated GPU infrastructure. The current wave of AI adoption is still in early stages. Most enterprises are running pilots and early production deployments. The transition to enterprise-wide AI deployment across all business functions represents the next phase of GPU data center demand, and it is larger than the current hyperscaler-driven wave.
Sovereign AI Infrastructure Programs
With governments pledging over $1.5 trillion in cumulative AI infrastructure commitments through end of year 2026, sovereign AI infrastructure is a decade-long construction program. Canada’s Sovereign Compute Infrastructure Program alone committed $705 million for national GPU supercomputing facilities in a single program cycle. Similar programs are active in France, the UAE, Saudi Arabia, India, Japan, and the UK. This is guaranteed demand with government balance sheets behind it.
AI Training vs. Inference Workloads: The Dual Growth Engine
AI training and AI inference are both growing, but at different rates and with different infrastructure profiles. Training runs on the largest GPU clusters for finite periods. Inference runs continuously at production volume. As the number of deployed AI models grows, inference GPU demand compounds. The AI Data Center GPU market is projected to reach $32.3 billion by 2030 at a 23.8% CAGR, with inference workloads driving an increasing share of that growth.
Data Center Modernization Across Every Sector
Every CPU-based data center serving an enterprise with AI ambitions is a future GPU data center upgrade. Data center modernization across healthcare, finance, manufacturing, government, and retail represents a multi-decade capital cycle. The broader data center GPU market is projected to reach $304.26 billion by 2034, reflecting the full scope of this modernization wave across every industry segment.
The Investment Decision in Front of You
GPU data centers are productive assets. They generate AI outputs at industrial scale, and those outputs translate into measurable revenue, cost reduction, and competitive advantage for the enterprises and governments that own or access them.
The financial case is clear. Enterprises running AI workloads at sustained utilization above 70% reduce total cost of ownership by 40 to 60% by moving from public cloud to GPU colocation or owned infrastructure. GPU acceleration compresses AI development cycles by five to 50 times. A well-deployed GPU data center delivers hardware ROI above 60% over five years, with compounding returns from the AI products it enables.
The strategic case is equally clear. The GPU data center market grows from $36.88 billion in 2026 to $124.19 billion by 2032. Sovereign AI programs commit over $1.5 trillion in infrastructure investment. Power supply companies see a generation-defining demand surge. Every major enterprise faces an AI infrastructure decision in the next 24 months. The organizations that make that decision with clarity and discipline, choosing the right deployment model for their workload profile, utilization rate, and compliance requirements, will operate with a durable advantage as AI becomes the primary driver of competitive differentiation across every sector.
GPU data centers are not a bet on AI. They are the infrastructure layer that makes AI at enterprise scale economically rational. The business case is built. The market data confirms it. The question for your organization is which deployment path fits your specific situation, and how fast you move to build or access the GPU infrastructure you need.
If you are ready to act on that decision, Aptly Technology is the partner built specifically for this moment. Aptly is the only supplier trusted by Microsoft to build and support third-party hyperscale data centers, and it brings that same execution depth to enterprises and AI companies accelerating their GPU infrastructure programs. Its core offering covers the full buildout lifecycle: architecture validation aligned to your AI roadmap, racking, cabling, power-up, and burn-in at hyperscale, high-performance InfiniBand and Ethernet networking integration, and ongoing operations benchmarked for 24×7 reliability.
Beyond the physical build, Aptly’s AI Workload Deployment and Optimization team tunes GPU cluster throughput, latency, and cost efficiency to eliminate idle compute and maximize ROI on your infrastructure investment. With a global delivery footprint spanning the US, India, China, Canada, and Europe, and certifications including ISO/IEC 42001, ISO 27001, and SOC2, Aptly gives you enterprise-grade trust from day one. Contact Aptly today to start your GPU data center buildout.
Frequently Asked Questions (FAQs): GPU Data Center Investment
- Should companies invest in GPU data centers in 2026?
- Yes, if your AI workloads run at sustained utilization above 65 to 70%. At that utilization level, GPU colocation or owned GPU infrastructure costs 40 to 60% less than equivalent public cloud spend over a three-year horizon. If your workloads are variable or you are in early AI experimentation, GPU-as-a-Service or cloud GPU access gives you flexibility without capital commitment.
- What is the ROI of GPU infrastructure for enterprises?
- Five-year hardware ROI benchmarks show NVIDIA GPU deployments achieving 61.4% ROI, AMD at 68.4%, and Intel at 57.1% in full cost accounting. Beyond hardware ROI, GPU infrastructure accelerates AI model training by five to 50 times compared to CPU equivalents, compressing time to market for AI products and creating compounding competitive advantages in AI-intensive sectors.
- Why are enterprises building GPU data centers instead of using cloud?
- CIOs are moving production AI workloads from public cloud to GPU colocation for three primary reasons: cost predictability (colocation is 60 to 70% of equivalent cloud cost at scale), compliance control (data residency requirements for regulated industries), and deterministic performance (no noisy-neighbor effects on production AI inference). Cloud remains the right choice for burst workloads and early-stage AI programs.
- How do GPU data centers support generative AI at enterprise scale?
- GPU data centers provide the high-density compute, high-bandwidth interconnects, and specialized cooling infrastructure that generative AI infrastructure requires. Large language model training runs across thousands of GPUs in parallel, a workload that CPU infrastructure cannot economically support. GPU clusters connected via InfiniBand or high-bandwidth photonic networks enable the distributed training and inference pipelines that production generative AI systems depend on.
- What are the advantages of GPU data centers over traditional data centers?
- GPU data centers deliver up to 10x AI workload acceleration, support power densities of 30 to 130+ kW per rack versus 8 to 15 kW for traditional facilities, provide the specialized network fabric required for distributed AI training, and enable business models (AI factories, GPUaaS, AI inference services) that CPU-based data centers cannot support.
- How much does it cost to build a GPU data center?
- A 2 MW prefabricated GPU data center costs approximately $8 million and deploys in 12 months. Traditional construction for the same capacity runs $14 million over 30 months. GPU hardware dominates total cost: eight NVIDIA H100 GPUs per rack at $200,000 to $400,000 per rack. Facility costs (power, cooling, networking, shell) add $1 to $3 million per MW of capacity in most markets.
- Which industries need GPU data centers the most?
- Financial services (fraud detection, algorithmic trading), healthcare (drug discovery, medical imaging), manufacturing (predictive maintenance, digital twins), autonomous vehicle development, and media and entertainment (generative AI content, rendering) deliver the highest ROI from GPU data center investment. Government and defense agencies represent the fastest-growing sovereign demand segment globally.
- Are GPU data centers the future of enterprise AI?
- Jensen Huang’s AI factory thesis at GTC 2026 frames the answer clearly: data centers that do not produce intelligence will eventually be replaced by those that do. The GPU data center is not a transition technology. It is the production infrastructure for the AI economy. Every enterprise with meaningful AI ambitions will either own GPU infrastructure, contract GPU colocation capacity, or access GPU clusters through a service provider. There is no fourth option at scale.
- How do GPU data centers enable AI factories?
- AI factories are GPU data centers operating as integrated AI production systems. They combine GPU clusters for training, GPU inference racks for production deployment, high-bandwidth storage for model and dataset management, specialized AI operating systems (like NVIDIA Dynamo), and energy infrastructure rated for continuous high-density operation. The AI factory model treats intelligence generation as an industrial production process, with GPU data centers as the factory floor.
- How can enterprises scale AI workloads using GPU infrastructure?
- Start with a utilization analysis. If your current AI workloads run above 65% sustained GPU utilization, move immediately to colocation or owned GPU infrastructure. For scaling, adopt a hybrid model: own or colocate baseline production capacity, use cloud GPU for burst. Invest in AI workload optimization and GPU scheduling software to maximize utilization rates before adding new hardware. Build GPU colocation or ownership into your AI infrastructure roadmap as a three-year capital commitment, not a year-by-year operating decision.




