

AI Data Security Starts Where You Think It Ends
Your AI pipeline is only as secure as its weakest data touchpoint. Secure AI development begins at the architecture stage, not after your first breach. That is the reality every security team confronts in 2026. Training datasets, fine-tuning corpora, inference endpoints, vector databases, model artifacts. AI data security and privacy failures do not announce themselves. They surface weeks later in a compliance audit or a regulatory notice. Each one is a target. Each one carries sensitive data that adversaries actively seek to extract, manipulate, or poison.
Data classification is the first control your team needs to implement before a single byte enters a training pipeline. AI data security is the practice of protecting that entire chain. Without proper data classification, your pipeline treats a social security number the same way it treats a product SKU. It covers not just the model itself, but the data flowing into it, the pipelines processing it, and the infrastructure running it. A single unsecured environment variable in a CI/CD pipeline can expose your training data to a public repository. A misconfigured vector database can leak proprietary business context through a RAG application. The risks are concrete and the consequences are measurable.
This guide gives you a practical, framework-aligned approach to AI data security best practices. It covers the threat landscape, the frameworks your security team needs to know, the technical controls that matter most, and how you implement them in regulated enterprise environments.
Why AI Data Security Is Different from Traditional Security
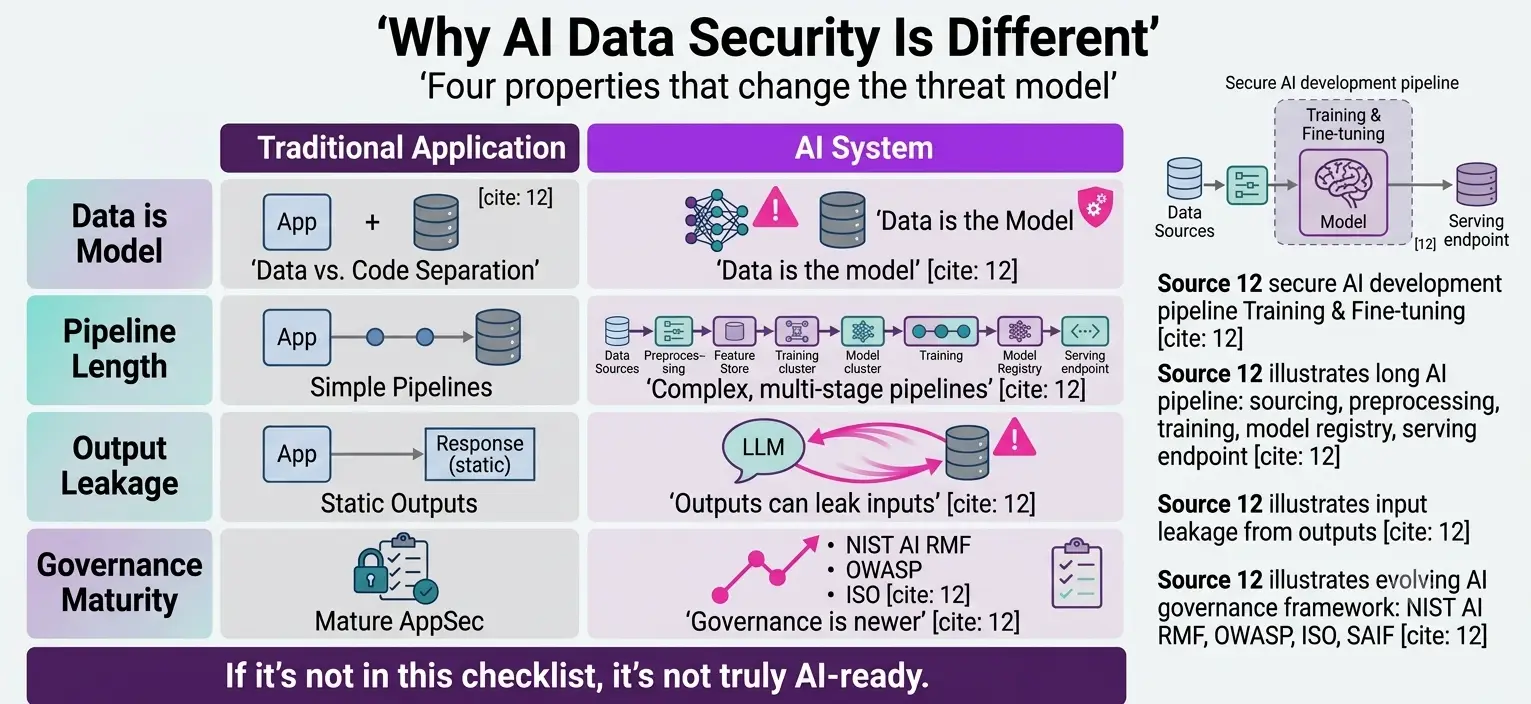
Traditional application security assumes a relatively static system: code runs, data is queried, outputs are returned. AI systems break that assumption. The model itself is a data artefact that encodes patterns learned from sensitive training data. Attackers who extract the model weights may reconstruct that data. That is a fundamentally different threat surface.
There are four properties of AI systems that create unique security challenges:
- Data is the model: In traditional systems, code and data are separate. In AI, training data shapes model behavior. Poisoned or stolen training data is an attack on the model itself.
- Pipelines are long: AI development pipelines connect data sources, preprocessing code, feature stores, training infrastructure, model registries, and serving endpoints. Each connection is an attack surface for pipeline and infrastructure security teams to manage.
- Outputs can leak inputs: Language models trained on sensitive data can regurgitate that data verbatim when prompted correctly. This is the data leakage prevention challenge specific to AI.
Governance is newer: AI governance frameworks are maturing rapidly, but enterprise teams are still catching up. Most organizations deploy AI faster than they build AI security controls around it.
Why AI Data Security is Different
According to GitNexa’s Enterprise AI Security Guide 2026, the top AI security risks in 2026 include data poisoning, prompt injection, model extraction, and insider data exfiltration through AI pipelines. None of these threats fit cleanly into traditional WAF or SIEM categories.
The AI Security Frameworks You Need to Know
Before you build technical controls, you need a governance architecture. These are the frameworks that define AI data security at the enterprise level.
NIST AI Risk Management Framework (AI RMF)
The NIST AI RMF is the most widely adopted AI governance framework in the United States. It organizes AI risk management into four functions: Govern, Map, Measure, and Manage. For AI data security teams, Govern establishes your policy and accountability structure, Map identifies data flows and sensitive assets, Measure quantifies risk across your AI inventory, and Manage implements and monitors controls.
NIST recommends starting with an AI system inventory: every model, dataset, and integration in your environment. Then classify each system by risk level. High-risk systems processing sensitive data get the most rigorous controls first.
OWASP LLM Top 10
The OWASP LLM Top 10 provides an engineering-level vulnerability taxonomy for large language model applications. The top risks include prompt injection, insecure output handling, training data poisoning, model denial of service, and sensitive information disclosure. Every team building generative AI applications needs this list in their threat model.
OWASP also published the Agentic Top 10 in 2025, covering AI agents specifically: agent hijacking, memory poisoning, and tool abuse are the leading concerns for autonomous AI systems.
ISO 42001 and Cloud Security Alliance
ISO 42001 is the first international standard for AI management systems. It provides a certifiable framework for AI governance, covering policy, risk management, data handling, and continuous improvement. Enterprises in regulated sectors increasingly require ISO 42001 alignment in vendor contracts.
The Cloud Security Alliance AI Safety Initiative extends cloud security principles to AI workloads, with specific guidance on secure machine learning pipelines, AI supply chain risk, and shared responsibility models for cloud-hosted AI.
Google SAIF and Microsoft Responsible AI
Google’s Secure AI Framework (SAIF) defines six core principles for AI data security: expanding security foundations to include AI systems, extending detection to AI-specific threats, automating AI-specific defenses, harmonizing platform-level controls, adapting controls to business-specific risks, and contextualizing risks end to end.
Microsoft’s Responsible AI framework adds transparency, fairness, accountability, and inclusiveness as governance pillars. For enterprise teams, Microsoft and IBM both publish detailed AI security guidance that complements NIST and OWASP at the implementation level.
AI Data Security Best Practices: The Core Technical Controls
This section covers the specific technical controls that form the backbone of AI data security in enterprise development pipelines. Apply these in order of risk priority.
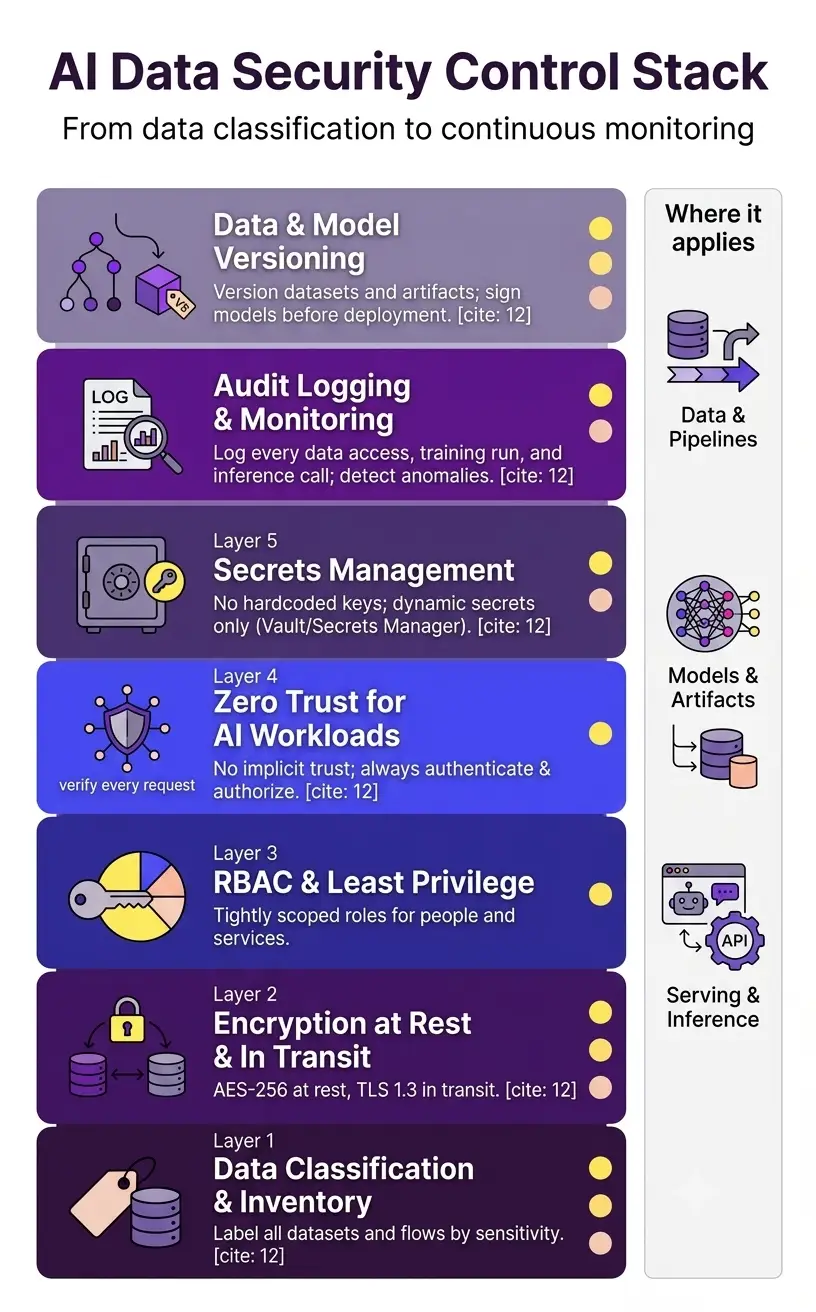
1. Data Classification and Inventory
You cannot protect data you have not classified. Start by tagging every dataset and data source that enters your AI pipeline with a sensitivity label: public, internal, confidential, or restricted. Apply these labels at ingestion and carry them through every pipeline stage.
Data classification directly controls what data trains which models. Restricted data (PII, PHI, financial records, trade secrets) should never enter a shared training environment without explicit access controls, anonymization, or synthetic substitution.
2. Data Encryption: At Rest and In Transit
Data encryption is the baseline control for AI data protection. Implement AES-256 encryption for all training data, model artifacts, and vector embeddings stored at rest. Use TLS 1.3 for all data in transit between pipeline components. For particularly sensitive workloads, GitNexa recommends secure enclaves and customer-managed encryption keys (CMK) for model storage and cross-region replication.
Cryptographic signing of model artifacts before deployment to production adds a second layer of assurance. Any model artifact that fails signature verification does not get promoted to serving infrastructure.
3. Role-Based Access Control (RBAC) and Least Privilege
Role-based access control is the primary access management mechanism for AI pipelines and in your AI Data Security strategy. Every service, agent, and human user in your pipeline gets the minimum permissions required for its specific function. Your ingestion worker needs write access to the data store but never delete access to the model registry. Your inference service needs read access to the model but never access to raw training data.
Pair RBAC with short-lived credentials. Time-bound, scoped tokens that rotate automatically prevent the credential theft attacks that remain among the most common vectors for pipeline compromise. Cycode’s 2026 AI Security report explicitly recommends auditing AI permissions on the same quarterly cycle as human identity access reviews.
4. Zero Trust Security for AI Workloads
Zero trust security assumes breach. Every request, whether from a developer, a service account, or an AI agent, is authenticated and authorized based on current context, not network location. For AI pipelines, this means no implicit trust based on VPN membership or internal IP address.
Implementing zero trust for AI workloads involves three principles. First: verify explicitly, using identity, device health, and request context for every access decision. Second: least privilege access, scoped to the minimum required for each service. Third: assume breach, with comprehensive monitoring, logging, and rapid credential rotation. HashiCorp Vault is the leading platform for implementing zero trust secrets management in AI infrastructure, providing dynamic secrets, policy-based access, and full audit logging.
5. Secrets Management
API keys, database credentials, model access tokens, and cloud service credentials are secrets. Hardcoding them in pipeline configuration files or environment variables is one of the most common causes of AI data leakage. Secrets management tools centralize, rotate, and audit access to every credential in your pipeline.
HashiCorp Vault, AWS Secrets Manager, and Azure Key Vault are the enterprise standards. Every AI pipeline component, including training scripts, data loaders, model serving endpoints, and orchestration workflows, should retrieve credentials dynamically at runtime rather than loading them from static configuration.
6. Audit Logging & Continuous Monitoring
Audit logging creates the evidentiary trail required for AI compliance and security investigations. Log every access to training data, every model inference call for high-risk systems, every pipeline execution, and every permission change. Centralize these logs in a SIEM platform like Splunk or Elastic.
Continuous monitoring goes beyond logging. Deploy anomaly detection on model outputs to catch behavioral drift that might indicate data poisoning. Monitor cross-tenant access patterns in vector databases. Set up alerts for unexpected data flows between pipeline components. This is where AI risk management moves from policy to practice.
7. Data Versioning and Pipeline Integrity
Version-control all training and fine-tuning datasets. Tools like DVC (Data Version Control) and Delta Lake provide dataset versioning with integrity verification at each pipeline stage. When a security incident occurs, dataset versioning lets you identify exactly which training run used compromised data and roll back accordingly.
Version your model artifacts alongside your datasets. A secure machine learning pipeline treats model binaries with the same rigor as production code: signed, versioned, tested, and promoted through controlled stages. Kubernetes with RBAC, private VPCs for training workloads, and HashiCorp Vault for secrets form the standard architecture pattern for secure MLOps in 2026.
Generative AI Security: LLM and RAG-Specific Controls
Generative AI security introduces attack vectors that did not exist in traditional ML pipelines. If your organization is building or consuming LLM applications, including internal chatbots, RAG systems, AI agents, or fine-tuned models, these controls are specific to your threat surface.
How to Secure LLM Training Data
Training data for large language models often aggregates data from multiple internal sources: customer records, support tickets, internal documentation, code repositories. Before any data enters the training pipeline, apply these controls:
- Apply sensitivity filters to exclude PII, PHI, and confidential business data before training runs.
- Use differential privacy techniques to add mathematical noise to training data, reducing the risk of verbatim data memorization.
- Implement data provenance tracking so every training record has a verified source. Cycode recommends strict data provenance validation and anomaly detection on model outputs to catch behavioral drift from poisoned data.
- Test trained models for memorization using adversarial probing before deployment to production.
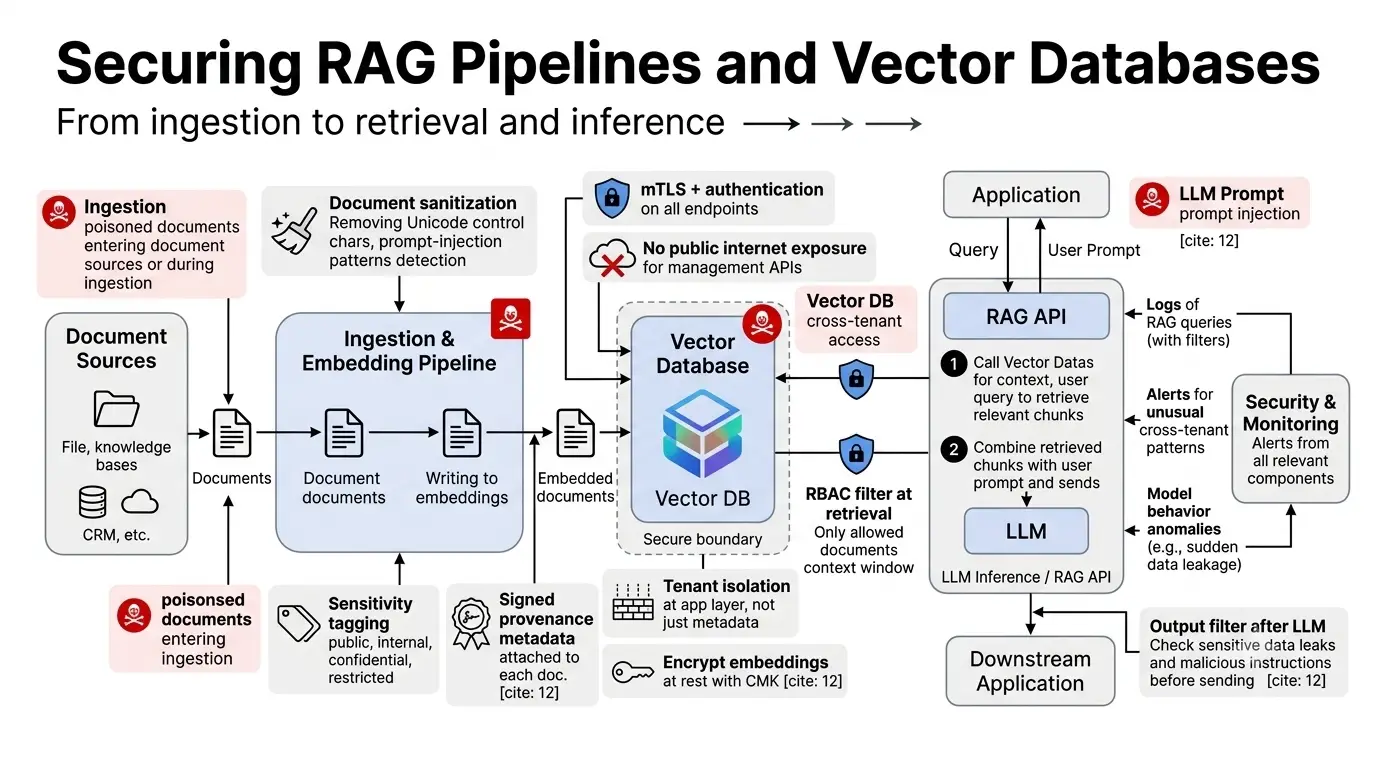
How to Secure RAG Applications and Vector Databases
Retrieval-Augmented Generation (RAG) systems combine LLMs with external knowledge bases stored in vector databases. This architecture creates two distinct attack surfaces: the ingestion pipeline and the retrieval layer.
For ingestion, RedFoxSec’s RAG security analysis recommends stripping Unicode control characters from all ingested documents, implementing LLM-based classifiers to detect injected instruction patterns in retrieved chunks, and using signed document provenance metadata to reject unsigned content at retrieval time.
For vector database security:
- Never expose ChromaDB, Weaviate, Qdrant, or Pinecone management APIs to the public internet.
- Enforce tenant isolation at the application layer, not just via metadata filters.
- Enable authentication and mutual TLS (mTLS) on all vector database endpoints.
- Encrypt all vector data at rest with customer-managed keys. For global clusters, encrypt cross-region replication separately.
- Implement document-level sensitivity tags. Tag documents before ingestion and enforce RBAC at retrieval time so users only retrieve documents they are authorized to see.
- Log all collection queries with full filter parameters and alert on anomalous cross-tenant access patterns.
Prompt Injection and Output Sanitization
Prompt injection attacks embed malicious instructions in user inputs or retrieved documents, directing the LLM to bypass safety controls, exfiltrate data, or execute unauthorized actions. This is the LLM security equivalent of SQL injection.
Treat all LLM outputs as untrusted input before passing them downstream. Apply output filters that check for code injection patterns, sensitive data patterns, and malformed commands. Use type-safe interfaces between AI systems and backend services so that outputs conform to expected schemas before triggering any action.
AI Pipeline Security: A Step-by-Step Implementation Guide
If you want to know how to secure sensitive data in AI development pipelines from the ground up, follow this phased approach. It reflects the implementation sequence recommended in the AccuKnox AI Security and Governance Guide 2026 and validated by the NIST AI RMF.
Phase 1: Discovery and Inventory
- Identify every AI workload, model, dataset, and integration in your environment.
- Classify each AI system by risk level: high risk (processing sensitive data or making consequential decisions), medium risk (internal productivity tools), low risk (fully sandboxed research environments).
- Map all data flows between pipeline components, flagging third-party APIs, shared datasets, and external integrations.
- Assign ownership for every AI system across security, engineering, and compliance teams.
Phase 2: Critical Security Controls
- Deploy zero trust access controls: least-privilege IAM roles, short-lived credentials, and mandatory multi-factor authentication for all pipeline access.
- Implement AES-256 encryption at rest and TLS 1.3 in transit for all training data, model artifacts, and vector databases.
- Configure secrets management via HashiCorp Vault or AWS Secrets Manager. Remove all static credentials from pipeline configuration.
- Enable centralized audit logging for all data access, model training runs, and inference calls.
- Apply data classification labels and enforce RBAC at each data access point.
Phase 3: Governance and Compliance
- Draft an AI governance framework aligned to NIST AI RMF. Assign board-level ownership of AI risk.
- Create model cards and data sheets for every production AI system.
- Map your AI systems to applicable regulations: GDPR, HIPAA, PCI-DSS, SOC 2, EU AI Act.
- Develop AI-specific incident response playbooks covering model compromise, data poisoning, and agent hijacking.
- Schedule quarterly AI permission audits and annual red-team exercises against LLM and agentic systems.
Phase 4: Continuous Monitoring and Optimization
- Deploy automated model validation in CI/CD pipelines: every model artifact is signature-verified before promotion to production.
- Run continuous anomaly detection on model outputs and data pipeline telemetry.
- Implement synthetic data substitution where possible to reduce exposure of real sensitive data in non-production environments.
- Retrain models regularly with validated, versioned datasets. Any training run that uses unvalidated data is blocked by pipeline policy.
AI Compliance & Security in Regulated Industries
AI compliance and security requirements vary by sector, but the underlying control framework is consistent. Here is how the main regulatory requirements map to technical controls across the industries with the strictest AI compliance needs in 2026:
| Industry/Regulation | AI Compliance Requirement | Key Technical Controls |
|---|---|---|
| Healthcare (HIPAA) | PHI protection, audit trails for AI decisions, minimum necessary access | Data encryption, RBAC, audit logging, data classification |
| Financial Services (PCI-DSS, SOX) | Data segregation, traceable AI decisions, examiner-ready audit records | Data versioning, model cards, SIEM integration, RBAC |
| EU (GDPR, EU AI Act) | Consent for personal data, transparency, human oversight for high-risk AI | Privacy by design, AI inventory, bias monitoring, incident response |
| Global Enterprise (SOC 2, ISO 42001) | Security, availability, confidentiality, AI management system certification | Zero trust, secrets management, model governance, continuous monitoring |
| Cross-sector (NIST AI RMF) | Govern, Map, Measure, Manage across AI lifecycle | Full AI inventory, risk classification, control testing, executive accountability |
The EU AI Act entered force in August 2024 and applies globally to any AI system serving EU users. It requires risk classification of all AI systems, transparency about how they function, and human oversight for high-risk decisions. If your AI data security posture does not include these governance controls, your compliance status in EU markets is at risk.
Glean’s 2026 industry compliance analysis identifies healthcare, financial services, pharmaceutical, energy, transportation, legal, and government as the sectors with the most demanding AI compliance and security requirements. Organizations in these sectors need a documented evidence package: technical documentation, validation reports, risk controls, and post-release oversight plans.
AI Security Checklist for Enterprise Deployments
Use this checklist to audit your current AI data security posture before deploying any AI system to production.
Data & Pipeline Controls
- All training and fine-tuning datasets are version-controlled with integrity verification.
- Sensitive data is classified and labeled before entering any pipeline.
- PII, PHI, and confidential data are excluded from training sets or replaced with synthetic equivalents.
- AES-256 encryption is applied to all data at rest. TLS 1.3 is enforced for all data in transit.
- Data provenance tracking is implemented: every training record has a verified source.
Access & Identity Controls
- RBAC is implemented with least-privilege scoping for every pipeline service and human user.
- Short-lived, time-bound credentials are used for all AI system access. No static secrets in configuration.
- Secrets management (HashiCorp Vault or equivalent) is deployed and all pipeline components retrieve credentials dynamically.
- Multi-factor authentication is enforced for all access to training infrastructure and model registries.
- AI system permissions are audited quarterly.
Model & GenAI Controls
- Model artifacts are cryptographically signed before deployment to production.
- LLM training data is tested for memorization using adversarial probing.
- RAG ingestion pipelines sanitize documents and apply signed provenance metadata.
- Vector database endpoints require authentication and mTLS. Management APIs are not internet-facing.
- Output filters check for injection patterns, sensitive data, and malformed commands before downstream execution.
- Prompt injection controls are implemented at the application layer.
Governance & Compliance Controls
- An AI system inventory exists: all models, datasets, agents, and integrations are documented.
- Every production AI system has a model card and data sheet.
- An AI governance framework aligned to NIST AI RMF or ISO 42001 is in place.
- Incident response playbooks cover model compromise, data poisoning, and agent hijacking.
- All applicable regulatory requirements (GDPR, HIPAA, PCI-DSS, EU AI Act) are mapped to the AI system inventory.
- Audit logs are centralized, retained for the required compliance period, and monitored for anomalies.
The Path Forward for Enterprise AI Data Security
AI data security is not a one-time project. It is a continuous discipline that evolves with your AI deployment footprint. Every new model, every new data source, every new AI agent expands the surface area you need to protect.
The organizations that build durable AI data security postures treat it as an engineering problem, not a compliance checkbox. They embed security controls into the pipeline at build time. They automate enforcement wherever possible. They apply the same rigor to AI systems that they apply to production application code.
Start with your highest-risk AI systems today. Classify your data. Implement RBAC and secrets management. Align to NIST AI RMF. Run a red-team exercise against your LLM applications. Build the governance layer before your AI footprint grows beyond your ability to audit it manually. The frameworks exist. The tools exist. The only variable is whether you build this discipline before an incident forces you to.
How Aptly Technology Helps You Build Secure AI From the Ground Up
Securing an AI pipeline is not just about tools. It requires the right infrastructure, the right architecture, and a partner who has built AI systems at scale before.
Aptly Technology is a Microsoft Gold Certified Partner and the only supplier trusted by Microsoft to build and support third-party hyperscale datacenters. Aptly works with HPE, NVIDIA, Lambda, and CoreWeave to deliver GPU infrastructure, AI workload optimization, and enterprise AI application development under one roof.
For security specifically, Aptly brings ISO/IEC 42001, ISO 27001, and SOC 2 certifications to every engagement. Its Cloud Security Services cover Identity and Access Management, end-to-end network security, Data Loss Prevention, data encryption, and governance and compliance controls, precisely the controls your AI pipeline needs at every stage.
Aptly also deploys MLOps and CI/CD pipelines with safety, governance, and compliance integrated at the build stage, not added after the fact. Whether you are standing up a GPU cluster, optimizing training workloads, or building a regulated AI application, Aptly compresses months of setup into weeks using pre-validated playbooks.
Talk to Aptly’s team today and build your AI pipeline on a foundation that security auditors and compliance teams will not push back on. Learn about our Zero Trust AI Infra Solutions & AI Agent Governance Strategies by clicking on the link-texts.
Frequently Asked Questions (FAQs)
- How do organizations secure sensitive data used by AI models?
- Organizations apply data classification at ingestion, encrypt data at rest and in transit, implement RBAC with least-privilege scoping, and use secrets management tools to prevent credential exposure. Sensitive data is excluded from training sets or replaced with synthetic alternatives where possible.
- What are the biggest security risks in AI development?
- The top risks are data poisoning (adversarial manipulation of training data), prompt injection (malicious instructions in LLM inputs), model extraction (stealing model weights through repeated queries), and insider data exfiltration through pipeline vulnerabilities. The OWASP LLM Top 10 catalogs these risks in detail.
- How can enterprises prevent AI data leaks?
- Deploy data loss prevention layers that scan and redact sensitive information from model inputs and outputs. Test trained models for memorization before deployment. Apply output filters to all LLM responses. Implement strict data provenance tracking and anomaly detection on model behavior.
- What security controls should be implemented for generative AI?
- At minimum: input sanitization and prompt injection defenses, output filtering before downstream execution, RAG document provenance validation, vector database authentication and mTLS, LLM training data filtering for PII, and audit logging for all inference calls on high-risk systems.
- How do you secure an AI training pipeline?
- Use a private VPC for training workloads, Kubernetes with RBAC, secrets management for all credentials, signed model artifacts, versioned datasets with integrity verification, and anomaly detection on training outputs. Sandbox all model updates before promoting to production.
- What are AI governance best practices for enterprises?
- Build an AI inventory, classify systems by risk, assign clear ownership, align to NIST AI RMF or ISO 42001, create model cards, develop AI-specific incident response playbooks, and establish continuous monitoring with automated compliance validation.
- How should organizations protect proprietary data when using LLMs?
- Route LLM calls through internal API proxies rather than exposing data directly to external model providers. Implement data residency controls. Use contractual safeguards that prevent your data from being used to train external models. Apply field-level redaction for the most sensitive data before it reaches any LLM context window.
- What compliance requirements apply to AI systems in regulated industries?
- In healthcare: HIPAA. In financial services: PCI-DSS and SOX. In the EU: GDPR and the EU AI Act. Globally for enterprise governance: SOC 2 and ISO 42001. The EU AI Act now applies to any organization serving EU users, regardless of where the organization is based.




