

Introduction
Enterprises are under pressure to adopt generative AI quickly. Leadership wants results, vendors promise fast success, and competitors keep launching new AI features. So many teams start with chatbot pilots and early demos.
The problem starts when those pilots move into production. Systems that worked in testing struggle with real users, enterprise data, security requirements, and rising infrastructure costs.
Successful enterprise generative AI deployment is not just about choosing the right model. It depends on infrastructure readiness, governance, security, and long-term operational planning. Many enterprise AI teams now realize that scalable AI systems require far more than model experimentation.
This guide explains what enterprises should prepare before scaling generative AI across the organization.
Why Most Enterprise Generative AI Deployments Stall?
Many enterprise AI projects work well during the pilot stage but struggle once they move into production. According to Gartner, 50% of GenAI projects fail because most teams focus on building the AI experience first and think about infrastructure, security, and governance later.
As a result, enterprises deal with unstable systems, governance gaps, and rising infrastructure costs later. An enterprise AI readiness framework helps organizations identify these risks before large-scale deployment begins. The following section outlines what actually need before enterprise generative AI deployment.
Step 1: Start with an AI Readiness Assessment
Before selecting vendors, frameworks, or foundation models, you should evaluate whether your organization is operationally prepared for AI at scale.
Evaluate Existing Infrastructure
Most enterprise environments were not built for generative AI workloads. Workloads such as vector search, real-time inference, and large-scale GPU processing can place significant pressure on existing infrastructure.
Because of this, enterprises should first evaluate whether their current systems can support long-term AI operations. Key areas to assess include:
- GPU infrastructure readiness
- Hybrid cloud AI capabilities
- Network latency requirements
- Storage performance for embeddings
- Container orchestration maturity
- AI workload isolation capabilities
This assessment becomes important once AI usage starts growing across teams and applications. Token-heavy inference workloads can quickly increase infrastructure costs and reduce system performance if the environment is not optimized properly.
To avoid these issues, infrastructure planning should focus on scalability and operational visibility from the beginning. Many enterprise engineering teams, including platform specialists at Aptly Technology, increasingly emphasize the importance of observability and long-term infrastructure planning before model selection.
Assess Data Readiness
Data silos are one of the most persistent obstacles in enterprise AI data preparation. When knowledge lives in disconnected systems, it cannot be surfaced by AI without deliberate integration tasks. Unstructured enterprise knowledge, inconsistent metadata, and outdated documents all degrade retrieval accuracy.
If your organization is planning to use retrieval-augmented generation (RAG), the quality of your vector databases and the documents indexed into them will determine how useful your AI actually is. RAG pipelines need clean, well-structured source material to return accurate, grounded responses.
- Who owns each dataset?
- What access controls apply?
- How is sensitive information tagged and handled?
These questions need answers before any model touches your data.
Identify High-Value Use Cases
Use-case prioritization matters more than adopting the newest model available. The enterprises that get real value from generative AI tend to start with the following well-defined problems and build operational depth before expanding scope.
- Enterprise search
- Customer support copilots
- Internal knowledge assistants
- Engineering productivity tools
AI-powered workflow automation is another strong candidate for early deployment. The key is to pick use cases where the ROI is measurable, the data is available, and the failure mode is tolerable.
Step 2: Build the Right Enterprise AI Infrastructure
Infrastructure determines whether AI remains experimental or becomes operationally sustainable. The following sections outline the foundational infrastructure decisions enterprises must address before enterprise generative AI deployment.
Choose Between Public, Private, and Hybrid AI
Different enterprise generative AI deployment models introduce different operational tradeoffs.
| Deployment Type | Benefits | Challenges |
|---|---|---|
| Public API-based AI | Faster rollout, lower upfront cost | Privacy concerns, data residency risk, vendor dependency |
| Private AI deployment | Better control, stronger security, data never leaves your environment | Higher operational complexity, GPU infrastructure costs |
| Hybrid cloud AI | Flexibility to mix workloads, burst to cloud for scale | Integration overhead, governance complexity across environments |
Private LLM deployment for enterprises is gaining ground, particularly in regulated industries where data cannot transit third-party inference endpoints. Enterprise LLM deployment on private infrastructure requires more upfront work but gives you full control over access, logging, and model versions.
Core Components of Enterprise AI Architecture
A production-grade enterprise AI architecture typically includes several layers working together. Here are the components you need to plan for:
- Model serving infrastructure: the compute layer that hosts and runs inference
- API gateways: centralized control points for authentication, rate limiting, and logging
- LLM orchestration layers: systems like LangChain or custom middleware that coordinate model calls, tools, and memory
- Vector databases: purpose-built storage for embeddings used in RAG pipelines
- RAG pipelines: retrieval systems that ground model outputs in your enterprise knowledge base
- AI observability platforms: tools that monitor model behavior, cost, and drift in production
- Prompt management systems: structured storage and versioning for prompts used across applications
LLM orchestration is underestimated in early planning. As you add more models, tools, and retrieval sources, the orchestration layer becomes a critical piece of your architecture and one that needs to be designed for observability from the start.
Plan for Scalability Early
Generative AI workloads grow rapidly after internal adoption expands. Many enterprises underestimate how quickly token consumption and GPU utilization increase.
Scalability planning should address:
- Multi-model orchestration
- GPU optimization
- Latency management
- Cost predictability
- Inference throughput
- Storage expansion
Planning early helps reduce future operational disruptions. Organizations that delay scalability planning often encounter runaway infrastructure spending or degraded user experiences.
These considerations represent some of the best practices for enterprise generative AI deployment because scalability failures typically emerge after AI becomes business-critical.
Step 3: Build an AI Governance Framework
Governance is becoming a core requirement for enterprise generative AI deployment. Without governance, enterprises cannot manage model accountability, compliance enforcement, or operational consistency.
Establish A Governance Framework
It should usually include:
- Model approval workflows
- Prompt governance standards
- Human review processes
- Audit trails
- Usage policies
- Risk classification systems
AI governance requirements for enterprises continue to evolve alongside emerging regulations, which makes proactive planning increasingly important.
Address Compliance and Regulatory Requirements
Depending on your industry, compliance requirements will directly constrain your deployment architecture.
- GDPR affects how you handle EU personal data in AI pipelines.
- HIPAA imposes strict controls on any system that processes protected health information.
- SOC 2 certification requirements often extend to AI systems that touch customer data.
Enterprise AI security and compliance requirements need to be mapped against your deployment architecture before you finalize vendor choices.
Manage Model Risks
Generative AI introduces operational risks that traditional enterprise applications rarely encounter. Examples include:
- Hallucinations
- Prompt injection attacks
- Bias amplification
- Data leakage
- Shadow AI usage
These represent some of the biggest challenges in enterprise generative AI deployment today. AI security for enterprises now requires AI-specific threat modeling alongside traditional cybersecurity practices.
Step 4: Enterprise AI Security Must Be Designed Upfront
Security architecture should be part of the initial enterprise generative AI deployment design.
Secure Data Access and Permissions
Role-based access control (RBAC) needs to extend into your AI systems. Not every user should be able to query every data source through an AI interface.
- Identity-aware AI systems check who is asking before deciding what the model can retrieve or generate.
- Encryption standards for data at rest and in transit need to apply to AI pipelines just as they do to traditional applications.
- Tenant isolation is critical in multi-tenant AI deployments where different business units or customers share infrastructure.
- Secure inference pipelines ensure that model inputs and outputs are not exposed to unauthorized observers.
Protect Against Emerging AI Threats
The threat landscape for AI systems is evolving quickly.
- Prompt injection attacks can hijack model behavior if not defended against at the architecture level.
- Sensitive data exposure through model outputs requires careful output filtering and content classification.
- Third-party model risks arise when you use external inference APIs.
- Plugin and tool vulnerabilities are a growing concern as AI systems gain the ability to call external services.
Engineering teams building enterprise AI systems are increasingly prioritizing AI threat modeling alongside traditional cloud security practices.
AI Observability and Monitoring
You cannot secure what you cannot observe. AI observability in production means:
- Tracking model drift over time
- Analyzing prompt patterns for anomalies
- Monitoring inference costs against budget
- Flagging hallucinations or policy violations.
Usage analytics help you understand how the system is actually being used.
Step 5: Don’t Ignore Change Management and Team Readiness
Operational readiness also depends on organizational alignment, governance ownership, and workforce preparation.
Align IT, Security, and Business Teams
Enterprise AI initiatives often fail because departments operate independently. Security teams, platform engineers, legal departments, and business units must share governance responsibilities.
Cross-functional collaboration improves:
- Governance consistency
- Deployment prioritization
- Operational accountability
- Risk management
- AI platform operations
Shared ownership prevents fragmented enterprise AI implementation strategies.
Upskill Teams for AI Operations
Most enterprise teams still lack operational AI expertise. Organizations should invest in practical AI operations training before scaling deployments.
Important capability areas include:
- Prompt engineering
- LLMOps practices
- AI infrastructure operations
- AI security practices
- AI observability workflows
Step 6: Define ROI Before Scaling Generative AI
Enterprises deploy AI before defining measurable business outcomes. The result is that success becomes subjective. Defining ROI criteria upfront anchors your AI investment to real business value.
Identify Success Metrics
The right metrics depend on your use case, but they should always be concrete and measurable. Here are examples across common enterprise generative AI deployment scenarios:
- Productivity gains: time saved per task for knowledge workers or support agents
- Reduced support load: deflection rate for Tier 1 support queries handled by AI
- Faster knowledge retrieval: time to answer for internal search queries
- Developer efficiency: code review time, PR cycle time, or time to first working prototype
- Operational automation: volume of manual process steps replaced by AI-assisted workflows
Measure Operational Efficiency
Beyond business outcomes, operational metrics tell you whether your AI infrastructure is running well. Cost per inference, GPU utilization rates, and token economics help you understand the true cost of each AI interaction. AI operational overhead is often underestimated in initial business cases.
Enterprise Generative AI Deployment Checklist
Before moving any generative AI workload to production, verify each item below. This enterprise generative AI deployment checklist covers the areas most likely to create problems when skipped:
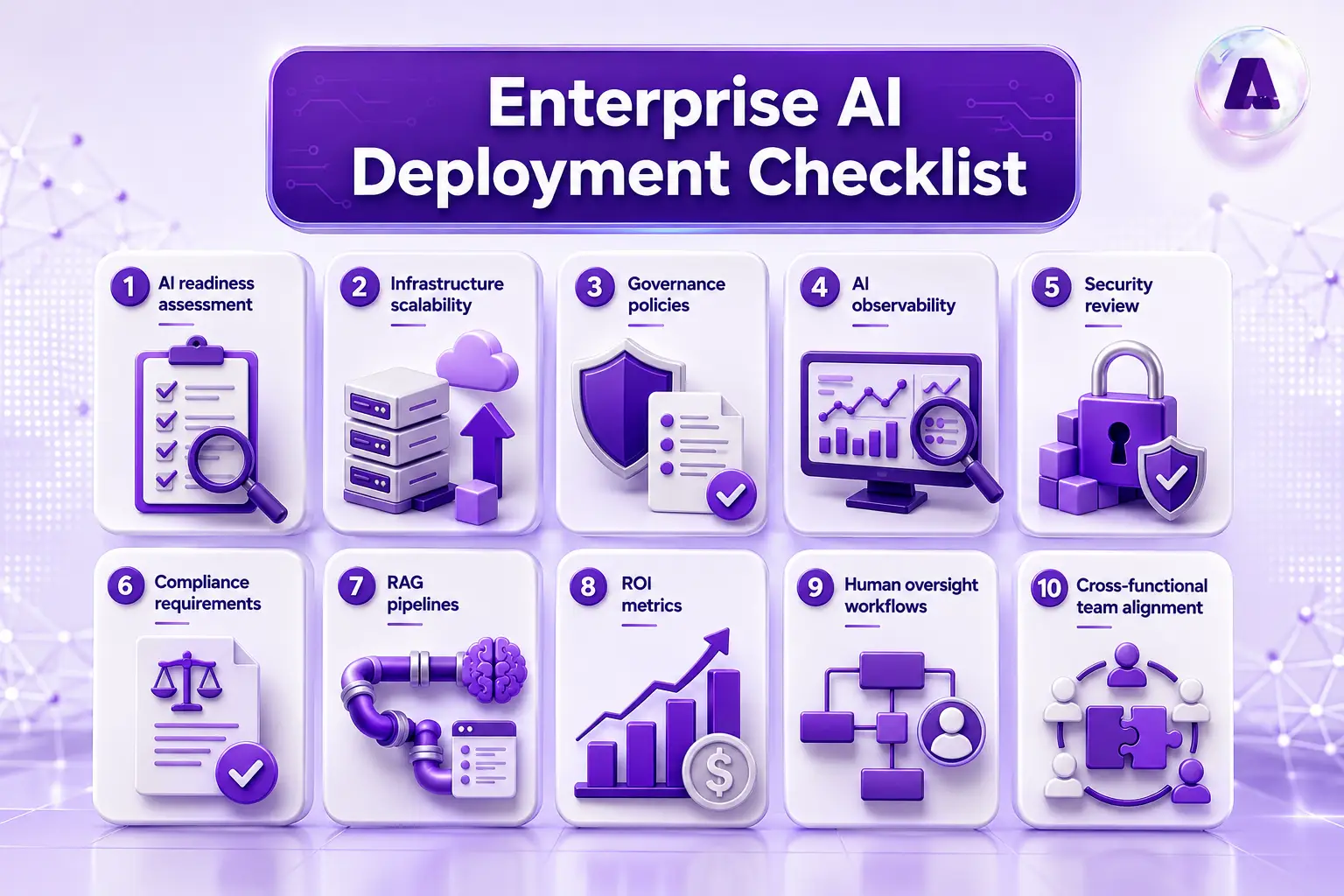
- AI readiness assessment completed across infrastructure, data, and use cases
- Infrastructure scalability validated under realistic load projections
- Governance policies defined: model approval, prompt management, audit trails
- AI observability implemented: drift monitoring, cost tracking, hallucination flags
- Security review completed: RBAC, encryption, threat modeling, tenant isolation
- Compliance requirements mapped: GDPR, HIPAA, SOC 2, data residency
- RAG pipelines tested with production-quality data at expected query volumes
- ROI metrics established with baseline measurements in place
- Human oversight workflows enabled for high-stakes outputs
- Cross-functional team alignment confirmed across IT, security, and business units
Conclusion
Enterprise generative AI deployment success depends more on operational readiness than choosing the latest model. The organizations seeing durable returns from generative AI are not necessarily using the most capable or newest models. The governance layer, the security architecture, and the observability tooling is what separates a production AI system from a prototype that never quite made it.
As enterprise AI initiatives mature, engineering-focused organizations like Aptly Technology are helping highlight a broader industry reality.
Ready to assess your enterprise AI readiness?
Start with your infrastructure and governance gaps—those are the decisions that will determine everything else.
FAQs
Q: What do enterprises need before deploying generative AI?
Enterprises need a clear AI readiness assessment covering infrastructure, data quality and governance, defined use cases with measurable outcomes, a security architecture, and a governance framework. Jumping straight to model selection without these foundations in place is one of the most common reasons enterprise AI deployments fail in production.
Q: How do companies prepare for generative AI adoption?
Preparation starts with an honest audit of existing infrastructure, data pipelines, and team capabilities. Companies should identify high-value use cases, establish governance policies, and align cross-functional stakeholders before committing to a deployment architecture.
Q: What infrastructure is required for enterprise AI?
Core infrastructure requirements include GPU compute, a containerized model serving environment, API gateways, LLM orchestration layers, vector databases for RAG pipelines, and AI observability platforms. The right mix depends on whether you are deploying on public APIs, private infrastructure, or a hybrid arrangement.
Q: How can enterprises deploy AI securely?
Secure enterprise AI deployment requires identity-aware access controls, encryption of data in transit and at rest, tenant isolation in multi-tenant systems, prompt injection defenses, and output filtering.
Q: What are the risks of deploying generative AI too early?
Deploying before readiness creates risks including:
- Unpredictable cost growth from unmodeled token economics
- Security vulnerabilities from bypassed controls
- Regulatory exposure from non-compliant data handling
- Reputational damage from hallucinated outputs
- Shadow AI usage that bypasses governance entirely.
Q: How do CIOs evaluate enterprise AI readiness?
CIOs should assess four areas: infrastructure scalability, data quality and accessibility, team capability, and governance maturity. Organizations with gaps in any of these areas typically face production failures within six to twelve months of initial deployment.
Q: What are the biggest challenges in enterprise AI deployment?
The most common challenges are data silos that prevent effective retrieval, governance gaps, security controls, and AI costs that become unpredictable at scale. Change management is equally challenging and often underinvested.
Q: How should enterprises govern AI models?
Model governance requires formal approval workflows before any model goes into production, human review processes for high-risk outputs, prompt versioning and management, audit trails for model interactions, and internal usage policies that cover shadow AI.
Q: What is the best enterprise AI deployment strategy?
The most effective strategy is phased and use-case-driven.
- Start with a narrow, well-defined problem where the data is available and the ROI is measurable.
- Build operational depth before expanding to additional use cases.
- Avoid the temptation to deploy broadly before the foundational layers are solid.
Table of content
- TL;DR
- Introduction
- Why Most Enterprise Generative AI Deployments Stall?
- Step 1: Start with an AI Readiness Assessment
- Step 2: Build the Right Enterprise AI Infrastructure
- Step 3: Build an AI Governance Framework
- Step 4: Enterprise AI Security Must Be Designed Upfront
- Step 5: Don’t Ignore Change Management and Team Readiness
- Step 6: Define ROI Before Scaling Generative AI
- Enterprise Generative AI Deployment Checklist
- Conclusion
- FAQs




