

Introduction: Why AI Workloads Should Matter in Your Enterprise IT Strategy
Enterprise AI has evolved rapidly into something truly transformative that impacts real changes. There are decisions being made with tangible impact by AI-powered workflows and insights. Once limited to isolated pilot projects or experimental endeavors, AI now forms a part of nearly half of technology leaders’ business strategies; nearly 50% reported full integration of AI into operations last year.
Yet here’s the hard truth: understanding what are AI workloads—and how to manage them at scale—separates winners from those burning budgets on idle GPU clusters.
AI workloads aren’t abstract algorithms – they are real compute-intensive engines powering everything from customer chatbots to supply chain forecast reports. CIOs are now confronting an unprecedented dilemma as enterprise AI workloads rapidly consume IT budgets; according to Gartner’s research, by 2028 over 50% of cloud computing resources will be dedicated to AI workloads while 53% of AI projects successfully move from prototype into production.
In this guide, you will learn:
What Are AI Workloads? Definition & Core Concepts
AI workloads are resource-intensive processes executing AI/ML tasks such as data ingestion and preparation, model fine-tuning, training on distributed GPU/CPU/TPU clusters, inference serving real time serving, monitoring and agentic orchestration.
Unlike traditional applications with predictable, static demands, AI workloads are characterized by:
- High compute intensity: Processing massive datasets—terabytes of unstructured text, images, audio, and video—across highly parallel architectures.
- Variable resource demands: Training workloads require intense compute bursts on thousands of GPUs, while inference workloads optimize ultra-low latency serving.
- Specialized infrastructure needs: High-bandwidth storage, low latency interconnects (InfiniBand, RoCE), and auto-scaling cloud capacity to handle unpredictable spikes.
Why AI Workloads Define Enterprise IT Strategy?
For CIOs, understanding AI workloads is critical because they directly determine:
- Architecture choices: Whether to deploy on-premises, public cloud, private cloud, or hybrid
- Cloud strategy: How much capacity, which regions, multi-cloud vs. single-vendor considerations
- Cost posture: GPU utilization, storage throughput, data transfer, and operational overhead
- Risk profile: Data residency, model governance, compliance, and responsible AI enforcement
- Speed to production: How quickly use cases move from pilot to scaled deployment in a production environment
Gartner reports that hybrid AI infrastructure–spanning data centers, colocation facilities, edge nodes and public clouds–has become the industry standard in businesses needing both control and elasticity. Without an approach tailored towards individual workloads or applications, organizations may experience GPU idleness, exorbitant cloud bills or extended PoC cycles.
Types of AI Workloads: Mapping the Enterprise Spectrum:
1. Data Preparation & Feature Engineering Workloads
Data workloads form the backbone of AI models’ performance. They ingest, cleanse, normalize and transform raw data so it can be consumed effectively by them.
Key activities:
- Batch ETL/ELT for historical data processing
- Streaming ingestion for real-time use cases (fraud detection, IoT monitoring)
- Feature extraction and vectorization for ML and LLM retrieval-augmented generation (RAG)
- Data labeling and curation for supervised learning
Infrastructure implications: Scalable storage (object and block), high-throughput I/O and cloud data platforms designed with artificial intelligence in mind are designed as “AI-first.” Gartner research highlights data quality, metadata management and observability as the three pillars of AI readiness.
Enterprise examples: Banking customer data lakes powering 360° views, healthcare ETL pipelines feeding clinical AI models, retail customer segmentation systems.
2. Model Training Workloads
Training workloads teach models to recognize patterns by iteratively adjusting parameters over large datasets. Deep learning and foundation models require massive parallel computation on thousands of GPUs with tightly connected networks and high-performance storage, which must all be combined for effective training workloads.
Characteristics:
- Long-running, highly parallel jobs with predictable but intense compute bursts
- Extreme sensitivity to GPU quality, interconnect bandwidth, and storage throughput
- Often span weeks for foundation models; days to hours for fine-tuning
Why it matters: Gartner notes double-digit growth in AI chip demand and emphasizes AI-ready infrastructure—including AI-optimized chips and fabrics—as a strategic imperative for CIOs. GPU supply mismatches are now a primary bottleneck in GenAI scaling.
Enterprise examples: LLM fine-tuning for personalized marketing recommendations, computer vision model training for autonomous systems, NLP models for document classification.
3. Inference & Serving Workloads
Inference workloads utilize trained models trained against new inputs to generate predictions, classifications, or generated content – from customer-facing chatbots to internal anomaly detection systems.
Deployment modes:
- Online/real-time inference: Latency-sensitive applications (chatbots, copilots, real-time recommendations)
- Batch inference: Periodic scoring (credit risk, churn prediction, nightly forecasts)
Design Considerations: Cost per inference, latency SLOs, and scaling behavior drive choices between GPU, CPU, or specialized accelerators. Gartner reports that inference-dominated AI workloads are now driving the 2026 surge in AI-optimized infrastructure spend.
Enterprise Examples: AI-powered customer support chatbots, real-time fraud detection for payments, recommendation engines in e-commerce, anomaly detection in manufacturing.
4. Classic ML & Analytics Workloads
Not all AI workloads are large language models. Classic ML workloads power forecasting, clustering, risk scoring, and optimization across finance, supply chain, and marketing.
Examples:
- Time-series forecasting (demand planning, revenue projections)
- Risk scoring models (credit risk, insurance underwriting)
- Reinforcement learning for dynamic pricing and resource allocation
- Clustering and segmentation for customer analytics
Infrastructure: Can run efficiently on CPUs with selective GPU use but still demand strong data pipelines and MLOps for lifecycle management.
Enterprise impact: These workloads are often overlooked in GenAI discussions but represent massive business value in established enterprises.
5. Generative & Agentic AI Workloads
Generative AI workloads include LLMs, multimodal models, and content creation. Agentic AI builds upon these foundations by adding orchestration, planning, tool-calling, workflows, and multi-step task completion so agents can perform multi-step tasks autonomously.
Workload patterns:
- LLM pre-training, fine-tuning, and RAG (Retrieval-Augmented Generation)
- Multimodal model training (text + image + audio)
- Agent workflows that are called APIs, tools, and other models, often spanning multiple clouds
Future Outlook: Gartner predicts that by 2029, 70% of enterprises will deploy agentic AI in IT operations, transforming how infrastructure is managed. This requires strong orchestration layers, guardrails, and governance to prevent misuse and cost overruns.
Enterprise examples: GenAI apps for document summarization, code generation copilots, autonomous IT operations agents, content creation systems.
AI Workload Lifecycle: From Discovery to Scale
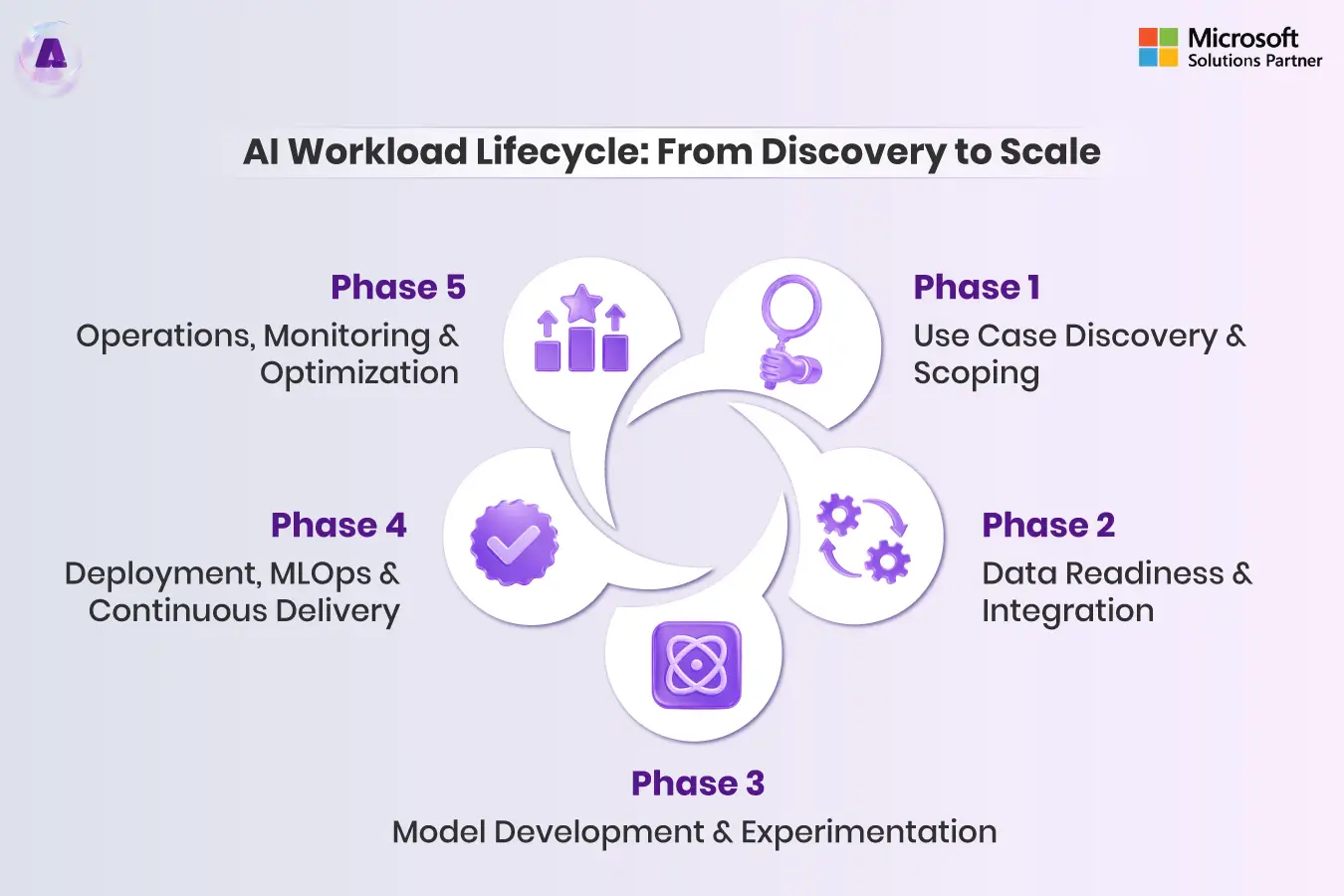
AI Workloads Lifecycle
The AI workload lifecycle is not linear; it’s a continuous loop demanding discipline and MLOps integration.
Phase 1: Use Case Discovery & Scoping
Enterprise AI begins by identifying high-value use cases and mapping them against workload characteristics like data availability, latency needs, regulatory constraints, and business ROI. Gartner emphasizes aligning AI initiatives with clear business outcomes rather than isolated experiments.
CIO questions to ask:
- Which workloads are differentiating vs. commoditized?
- Which requires sovereign or on-premises deployment vs. public cloud?
- What latency, throughput, and availability SLOs are required?
Phase 2: Data Readiness & Integration
Gartner has identified three pillars of AI readiness as essential to AI projects’ success: metadata management, data quality and data observability. This indicates that most AI-related initiatives fail not because of algorithms, but mostly due to fragmented, low-quality, or inaccessible data.
Priorities:
- Build AI-ready data platforms with governance and lineage
- Implement data quality checks and automated monitoring
- Rationalize data estates to reduce technical debt
Hard truth: Through 2026, 60% of AI projects will be abandoned without AI-ready data.
Phase 3: Model Development & Experimentation
This phase involves selecting architectures, experimenting with algorithms, and training or fine-tuning models. Gartner notes that operationalizing AI requires standardizing experimentation through MLOps practices.
Best practices:
- Use reproducible pipelines (code versioning, dependency management)
- Track experiments and hyperparameters with tools like MLflow
- Maintain shared feature stores for consistency
Phase 4: Deployment, MLOps & Continuous Delivery
MLOps brings DevOps principles—automation, CI/CD, monitoring—to AI workloads so models can be deployed, versioned, and updated consistently at scale. Gartner identifies MLOps as the “scaling catalyst” of AI.
Key components:
- Automated deployment pipelines (CI/CD) for models and data pipelines
- Model registries, canary releases, shadow deployments, and rollback strategies
- Version control for datasets, features, and training artifacts
Impact: Organizations are reducing time-to-production from 9 months to 7.3 months on average, though vast room for improvement remains.
Phase 5: Operations, Monitoring & Optimization
Once deployed, AI workloads must be monitored for performance, drifts, biases, security, and cost efficiency.
Focus areas:
- Workload observability: Latency, throughput, error rates, GPU utilization
- Data drift detection: Retraining triggers when model performance degrades
- Cost optimization (FinOps for AI): Workload scheduling, spot instances, model compression
- Governance and compliance: Audit trails, access controls, responsible AI enforcement
AI Workload Deployment: Cloud, Hybrid, Edge & On-Premises
Public Cloud:
Public cloud is the default home for experimentation and training, offering elastic GPU/TPU capacity and managed AI services.
Advantages:
- Instant access to thousands of GPUs and TPUs
- Managed MLOps platforms (SageMaker, Vertex AI, Azure ML)
- Fast iteration and low upfront capital
CIO concerns:
- Cost predictability and runaway spending
- Data residency and regulatory compliance
- Vendor lock-in for proprietary models
Adoption rate: PwC reports that 85% of technology leaders expect cloud budgets to grow, with AI/ML workloads as the primary driver.
Private Cloud & On-Premises:
Due to concerns related to data sovereignty, latency and IP protection, enterprises often opt to keep certain AI workloads on-premises or in private clouds. Training proprietary models on highly sensitive information (healthcare records, financial transactions or defense matters) often necessitates this decision.
Requirements:
- GPU-dense clusters with interconnects (InfiniBand/RoCE)
- High-speed fabrics for distributed training
- Modern data center infrastructure management (DCIM) for power, cooling, and capacity
Hybrid & Multi-cloud:
Gartner defines hybrid and multicloud deployments as supporting workloads consistently across enterprise data centers, colocation facilities, edge devices and public clouds. So, hybrid and multicloud deployments are now the norm!
Typical patterns:
- Train in public cloud; deploy latency-sensitive inference at the edge or on-premises
- Use multicloud to avoid single-vendor lock-in for foundation models and GPUs
- Maintain policy-driven, federated governance across environments
Edge & Distributed AI:
Edge workloads push models closer to data sources—factories, vehicles, retail stores—for ultra-low latency and resilience.
Examples:
- Industrial automation and predictive maintenance
- Smart city sensor networks
- Video analytics in retail or security
- Personalized recommendations at point-of-sale
Infrastructure: Smaller accelerators, local gateways, synchronized model management from central MLOps platforms.
AI Workload Optimization: Performance, Cost & Reliability
Architectural Optimization:
Right-sizing infrastructure: CIOs must analyze workloads (training vs. inference, batch vs. streaming) and match them to appropriate hardware, instances and storage tiers. Gartner emphasizes workload-aware design rather than generic “lift-and-shift” approaches.
Aligning AI, data, and cloud strategy: PwC highlights that many enterprises struggle to scale AI due to cloud and data strategies not meeting AI ambitions; successful AI scaling requires coordinated planning.
Cost & FinOps for AI:
Cloud cost and carbon optimization:
- Model compression and quantization to reduce inference compute
- Retrieval-Augmented Generation (RAG) to reduce token usage
- Instance right-sizing, spot instances, and reserved capacity
- Organizations increasingly track carbon KPIs alongside cost and performance
Budget shifts toward AI workloads: Cloud spend is growing as AI/ML workloads become primary drivers, requiring new financial governance models.
Performance & Reliability:
MLOps as a scaling catalyst: Gartner highlights MLOps as essential to scaling AI, providing automation, traceability and faster proof-of-concept (POC)-to-production cycles. Without MLOps in place, organizations would rely on manual processes which cannot scale.
Data pipeline quality: Poor data is among the top obstacles to AI adoption. CIOs must enforce data quality, lineage, and governance to maintain reliable AI workloads at scale.
Governance, Risk & Compliance:
Guardrails for generative and agentic AI: Gartner’s 2025 technology trends emphasize the twin imperative of using agentic AI for productivity while simultaneously setting safeguards to avoid misuse, data leakage, or hallucination risks.
Responsible AI frameworks: PwC’s AI predictions involve documenting model purpose, training data limitations and bias checks before aligning AI workloads with regulatory requirements.
Best Practices for Managing AI Workloads
- Classify & Prioritize Workloads: Map types of AI workloads to business value and infrastructure requirements. Distinguish between mission-critical, strategic, and experimental workloads.
- Build AI-Ready Infrastructure: Invest in GPU clusters, high-speed fabrics, NVMe storage, and auto-scaling cloud capacity. Design for hybrid operations from day one, not as an afterthought.
- Operationalize with MLOps & AI Engineering: Implement unified DataOps, MLOps, and DevOps pipelines. Use tools like Kubernetes for workload orchestration, MLflow for experiment tracking, and feature stores for consistency.
- Enforce Data Governance: Build AI-ready data platforms with metadata management, quality checks, and observability. Three pillars: metadata, quality, observability.
- Monitor & Optimize Continuously: Deploy workload observability (Prometheus, custom metrics). Monitor for data drift, model performance degradation, and cost overruns. Implement FinOps dashboards.
- Establish Governance & Risk Controls: Map regulations (GDPR, HIPAA, AI Act), enforce access controls, maintain audit trails, and implement human-in-the-loop checkpoints for critical decisions.
- Plan for Agentic AI: Prepare orchestration layers, guardrails, and policy engines for autonomous agent workloads. By 2029, 70% of enterprises will deploy agentic AI in IT operations.
Challenges of Implementing AI Workloads & Solutions + Case Studies
| Challenge | Root Cause | Solution | Related Case Studies |
|---|---|---|---|
| GPU Shortages & Bottlenecks | Explosive demand exceeds supply | Hybrid deployment,
Spot instances, Multi-cloud diversity |
CTO Magazine: Enterprise AI Hybrid Architecture Leading enterprises rely on Kubernetes-powered hybrid cloud environments with on-prem GPUs for baseline training and cloud bursting for peak seasons to optimize costs during shortages by automatically scaling across environments. |
| PoC Trap | 47% of projects stall before production | Invest in MLOps,
Enforce deployment standards, Prioritize ROI |
VisualPath: Recommendation System MLOps Case Study E-commerce company implemented MLOps pipelines to automate deployment/versioning/monitoring tasks and transition from manual Proof of Concept (PoC) failures to stable production with shorter cycles and reduced failure rates. |
| Data Drift & Model Decay | Unmonitored model performance degradation | Implement workload observability,
Automated retraining pipelines |
DQ Labs: Data Drift Mitigation Enterprise adopted continuous observability for schema/distribution monitoring plus automated retraining triggers with off-cycle scheduled retrains to identify drift early and maintain accuracy via scheduled off-cycle retrains. |
| Siloed Data | Legacy systems,
Fragmented ownership |
Modernize data platforms,
Implement centralized governance |
Deloitte/Nestlé: Data Lake Modernization Nestlé assimilate disparate on-premises systems into one centralized cloud data lake for advanced analytics and collaboration purposes by eliminating duplicate versions of truth/double data sets/duplicated versions of truth for advanced reporting purposes. |
| Cost Runaway | Idle GPUs,
Inefficient instance sizing |
FinOps dashboards,
Workload scheduling, Cost allocation |
WeTransCloud: GPU FinOps Optimization Organizations using FinOps for GPU workloads reported 25-40% savings by monitoring/underutilization detection, smart scaling and allocating, thus eliminating idle GPU waste. |
| Governance Gaps | No AI-specific controls or audit trails | Implement AI TRiSM,
Responsible AI frameworks, Policy engines |
ModelOp/Fidelity: AI TRiSM Implementation Fidelity Investments adopted Gartner AI TRiSM for governance/runtime inspection/policy enforcement to enhance model production 2x faster with 67% reduced management time and provide a scalable compliance framework. |
Future of AI Workloads: Agentic AI, Scale & Governance
Agentic AI represents the next frontier of artificial intelligence; autonomous agents that plan, execute, and iterate on complex tasks with minimal human input. Gartner forecasts that by 2029, 70% of enterprises will employ agentic AI in IT operations – drastically altering how infrastructure is managed and optimized.
For CIOs preparing today:
- Design orchestration layers for multi-step agent workflows
- Implement guardrails to prevent agent misuse and cost overruns
- Build observability into agent actions and decision trails
- Invest in responsible AI frameworks to manage agent risks
Conclusion: The Time to Modernize Is Now
Enterprise AI workloads offer your organization a chance for transformation while at the same time being an expensive expenditure. Gartner projects that by 2028, over 50% of cloud computing will be dedicated solely to AI workloads; yet only 53% of projects reach production.
The imperative is clear: Treat AI as first-class infrastructure. This means:
- Unify via AI engineering, bringing DataOps, MLOps, and DevOps together
- Hybridize deployments—design for on-prem, cloud, and edge from day one
- Operationalize with robust MLOps, workload orchestration, and observability
- Govern with AI TRiSM, responsible AI frameworks, and compliance controls
- Optimize relentlessly—cost, performance, risk, carbon footprint
AI workloads offer exponential business value, real-time decisions and productivity gains of 10x or more if managed properly; without proper AI workload management budgets may quickly evaporate into idle GPU clusters and long PoCs.
Frequently Asked Questions (FAQs)
- What are AI workloads in simple terms?
AI workloads refer to computational tasks–like data preparation, model training and real-time predictions–that power AI systems. They typically run on specialized hardware (GPUs and TPUs) and consume enormous amounts of both data and compute power.
- What are the main types of AI workloads?
The five core types are: (1) Data preparation & feature engineering, (2) Model training, (3) Inference & serving, (4) Classic ML & analytics, and (5) Generative & agentic AI. Each has distinct resource needs and deployment patterns.
- How do I optimize AI workloads for cost?
AI workload cost optimization involves right-sizing instances, using spot instances, implementing FinOps dashboards, model compression, batch inference, and monitoring GPU utilization. Gartner emphasizes that workload scheduling and auto-scaling are critical levers.
- What are the main challenges of implementing AI workloads?
Top challenges include GPU shortages, PoC-to-production gaps, data silos, model drift, and cost control. Through 2026, 60% of AI projects will be abandoned without AI-ready data. Solutions include MLOps, hybrid deployment, and data modernization.
- What infrastructure do I need for AI workloads?
Infrastructure requirements for AI workloads include GPU/TPU clusters, high-speed interconnects (InfiniBand/RoCE), NVMe storage, auto-scaling cloud platforms, data pipelines, and MLOps tools. Hybrid architectures are now standard.
- Can edge AI workloads scale to enterprise deployment?
Yes, edge AI workloads excel for low latency use cases (real-time predictions, IoT, industrial automation). Hybrid approaches—training in cloud, inferencing at edge—combine scalability with responsiveness.
- What is the AI workload lifecycle?
The lifecycle includes discovery → data readiness → model development → deployment (via MLOps) → monitoring and optimization → retraining. It’s continuous, not linear, and demands discipline across all stages.
- How does MLOps help with AI workload management?
MLOps for AI workloads automates training, deployment, monitoring, and retraining of models at scale. It reduces PoC-to-production time and enables reliable, auditable AI systems. Gartner identifies MLOps as the “scaling catalyst” of AI.
- What is workload orchestration in AI?
Workload orchestration via Kubernetes, Kubeflow or cloud-native tools automates allocation of compute resources, scheduling training and inference jobs and scaling capacity accordingly based on demand – an integral aspect of cost-efficiently managing diverse AI workloads.
- What is the future of AI workloads?
Agentic AI is rapidly altering the landscape. By 2029, 70 of enterprises will employ autonomous agents in IT operations requiring stronger orchestration, guardrails and governance to safely manage autonomous systems.




