

As generative AI (GenAI) continues to transform industries, more enterprises are exploring how to bring this powerful technology in-house. While public cloud solutions dominate the narrative, there’s a growing interest in deploying GenAI applications on-premises — especially small to midsize workloads where cost, performance, and data privacy are top of mind.
If you’re an infrastructure and operations (I&O) leader navigating this journey, understanding your compute, storage, and networking needs is essential. This guide will walk you through key considerations to help you design the right setup for on-prem Generative AI Infrastructure.
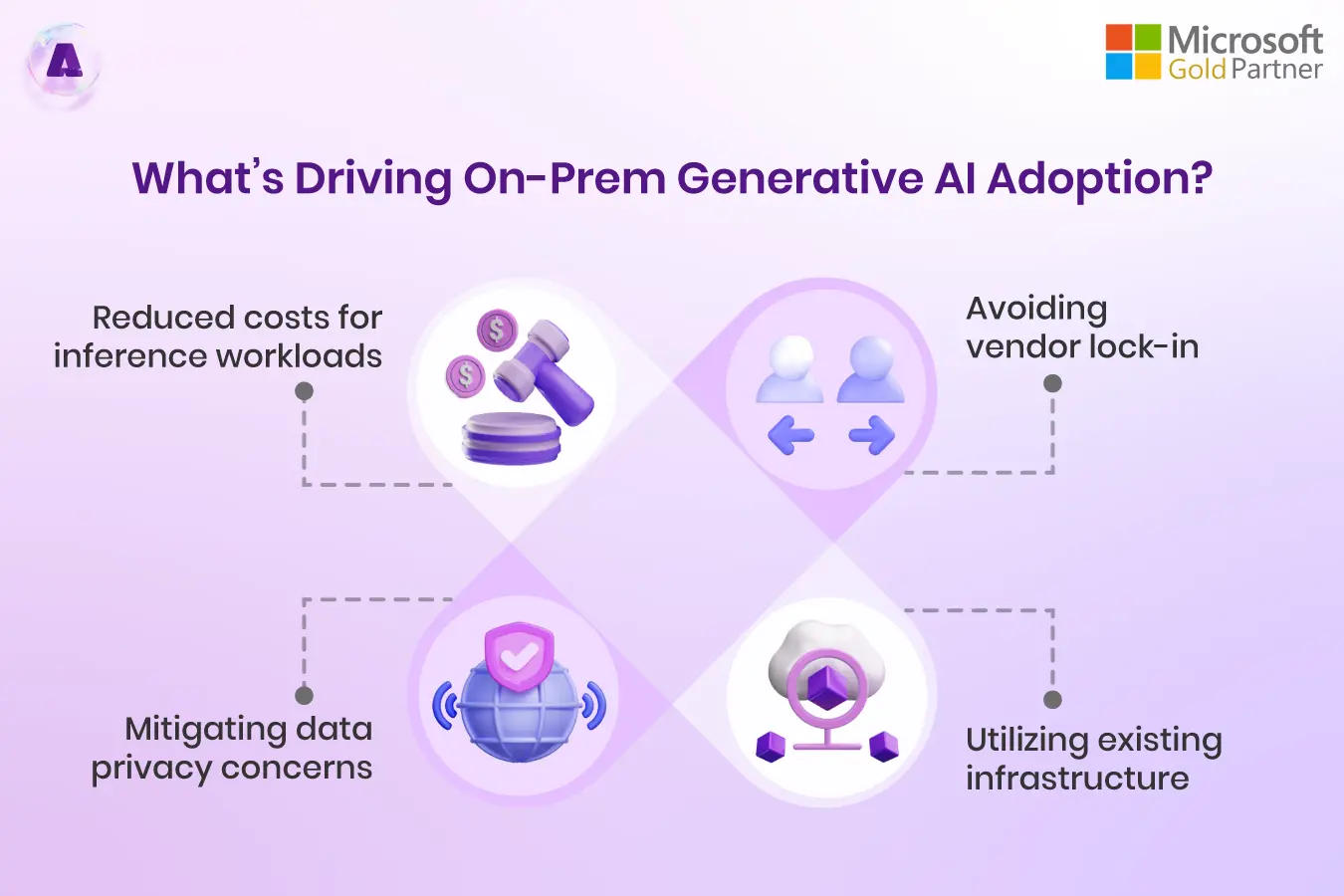
What’s Driving On-Prem Generative AI Adoption?
In most enterprise settings, the primary use case for on-prem Generative AI isn’t full-scale model training — it’s retrieval-augmented generation (RAG) and small-scale inference or fine-tuning. Large language model (LLM) training is still largely the domain of public cloud and GPU-as-a-service platforms due to massive compute demands. But for teams focused on inference or domain-specific customization, on-prem infrastructure is not only feasible — it’s smart.
Start With the Use Case, Not the Hype
Before diving into hardware choices, define what your GenAI application needs to do. Are you fine-tuning an existing model? Running high-volume inferences? Or simply augmenting responses with enterprise-specific data?
Smaller, less complex use cases don’t require exotic hardware. In fact, existing data center technologies — including AI-optimized CPUs, flash storage, and even commodity Ethernet — may be more than enough for your needs.
Choosing the Right Compute Stack
For GenAI, compute requirements depend on workload type (training vs. inference), model size, and real-time performance expectations.
Here’s what to keep in mind:
- CPUs & AI Accelerators: For lighter inference use cases, AI-optimized CPUs or cost-effective alternatives like AMD GPUs or Intel Gaudi can be suitable. Just remember, the broader software ecosystem around NVIDIA may be harder to replicate with other vendors.
- GPU Memory: Large models require substantial GPU memory, especially if you’re running concurrent inference workloads. Make sure you consider both model size and the number of users.
- Custom AI Chips: For ultra-specific needs, custom chips like Google TPUs or Cerebras’ Wafer-Scale Engine may offer performance boosts, though at the cost of higher complexity and integration overhead.
Storage: It’s Not Just About Speed
Flash-based enterprise storage can handle most GenAI workloads, but advanced use cases need more than just fast read/write speeds. Data management capabilities — like orchestration, aggregation, and curation — are just as critical.
If your team spends more time wrangling data than training models, consider investing in a storage solution that simplifies data preparation. You’ll thank yourself later.
Networking: Ethernet vs. InfiniBand Isn’t a One-Size-Fits-All Decision
InfiniBand has long been the go-to for high-performance AI workloads, but modern commodity Ethernet has come a long way — especially with technologies like RDMA over Converged Ethernet (RoCE). For small to midsize deployments, Ethernet is often good enough, more cost-effective, and easier to manage.
Evaluate your networking based on:
- Performance needs
- Scalability
- Physical footprint
- Supportability
Strategic Outlook: Why On-Prem Is Rising Again
According to Gartner, less than 2% of enterprises ran AI workloads on-premises in early 2025. But that number is expected to grow to over 20% by 2028. The message is clear: on-prem GenAI isn’t just a niche — it’s a strategic pivot for organizations balancing performance, cost, and privacy.
Practical Recommendations
- If you’re handling inference or RAG workloads, your existing infrastructure might already be up to the task.
- Don’t default to NVIDIA or public cloud without considering alternatives like AMD GPUs or AI-specific chips.
- Invest in storage that goes beyond performance to support rich data lifecycle management.
- Evaluate modern Ethernet options as realistic substitutes for InfiniBand in non-complex environments.
Final Thoughts
Bringing GenAI in-house isn’t about replicating public cloud capabilities. It’s about understanding your unique use case and tailoring your infrastructure accordingly. With careful planning, a small to midsize deployment can deliver high-impact GenAI capabilities — without overengineering or overspending.
On-prem GenAI is no longer a bold experiment. It’s a practical step forward — and it might just be the competitive edge your organization needs.
Table of content
- What’s Driving On-Prem Generative AI Adoption?
- Start With the Use Case, Not the Hype
- Choosing the Right Compute Stack
- Storage: It’s Not Just About Speed
- Networking: Ethernet vs. InfiniBand Isn’t a One-Size-Fits-All Decision
- Strategic Outlook: Why On-Prem Is Rising Again
- Practical Recommendations
- Final Thoughts




