

Introduction: Why AI Workload Cost Optimization Should be a Board-Level Priority
Enterprise AI has transitioned from experimental to implementation phase, with CIOs and CFOs jointly responsible not only for AI innovation, but also the economics of running these systems at scale. GenAI pilots, LLM-based copilots, and predictive models are now entering business-critical workflows–from customer support to supply chain and risk management–thus transforming from laboratory prototypes into essential parts of daily workflows.
Thus, organizations have begun to recognize an unpleasant truth: AI can be costly if left unmanaged. Training state-of-the-art models on multi-node GPU clusters, maintaining always-on inference endpoints and moving massive volumes of data can quickly turn into seven or eight figure annual line items. AI workload cost optimization is the difference between AI as a strategic asset and AI as an uncontrolled cost center.
In this guide, you will learn:
Why the Urgency?
- Gartner and industry analysts estimate that global AI spending will reach around $2 trillion USD by 2026.
- AI-optimized IaaS spend more than doubling in 2026 as organizations ramp up large-scale training and inference.
- Real-world telemetry shows that 30–40% of provisioned GPU capacity in many enterprises sits idle due to GPU overprovisioning, poor scheduling, and pipeline bottlenecks—creating direct idle GPU costs and eroding ROI.
With $2T in global AI spend projected and typical GPU utilization at 60-70%, billions of dollars are being wasted annually. Early adopters of cost optimization practices gain structural cost advantages and faster model iteration cycles.
The Core Challenge:
Without a structured AI workload cost optimization framework, enterprises risk:
- Exploding cloud AI bills/invoices
- Underutilized multi-node GPU clusters
- AI projects that meet technical benchmarks but fail to make financial reasoning
What Makes AI Workloads So Expensive?
Definition: Cost Drivers in Modern AI Workloads
AI workloads are inherently compute- and data-intensive. Training a large language model or a complex vision model typically involves:
- Massive parallel computation on specialized accelerators like NVIDIA A100/H100 in multi-node GPU clusters
- High-throughput storage for reading training data and writing checkpoints
- Significant network bandwidth for distributed training and data synchronization
On the inference side, even if the underlying model is trained only once, enterprises may run millions or billions of prediction calls per month across regions and channels. This shift from occasional experimentation to continuous operation is precisely why AI compute cost optimization is now a strategic imperative.
Why AI Workloads Are Expensive Compared to Traditional Workloads
Traditional business applications are often CPU-bound, predictable, and relatively easy to right-size. By contrast, AI workloads:
- Use accelerators that are several times more expensive per hour than standard instances
- Are highly sensitive to data pipeline design, which can leave GPUs idle while waiting on I/O
- Have variable and bursty patterns (especially during experimentation and retraining) that require careful AI workload scaling costs management
Analyses of real customer estates show that GPU resource optimization for AI is often immature: many teams provision “the biggest GPU” by default, leading to GPU overprovisioning, significant periods of idle GPU capacity, and unnecessary spending.
AI Training Vs Inference: Cost Profiles and Optimization Levers
| Aspect | Ai Training Cost Optimization | AI Inference Cost Optimization |
|---|---|---|
| Role in Spend | Most visibly expensive part of AI development upfront due to heavy compute and long runs. | Costs accumulate over time and often become the dominant expense with sustained traffic and global deployments. |
| Typical Workload Characteristics |
|
|
| Primary Cost Drivers |
|
|
| Optimization Focus | AI training cost optimization aims to reduce time-to-train and GPU hours consumed per experiment. | AI inference cost optimization aims to reduce per-request cost and total serving footprint over time. |
| Key Techniques |
|
|
| Time Horizon of Impact | Short-to-medium term: cost spikes around major training runs and experimentation phases. | Long-term: recurring operational cost that grows with adoption and user traffic. |
| Strategic Importance | Optimizing training costs enables faster experimentation, more iterations, and better models within a fixed budget. | A strong AI inference vs training cost comparison is foundational for AI workload cost optimization strategies for enterprises, helping align budgeting and architecture decisions with real usage patterns. |
Common Causes of GPU Underutilization and Waste
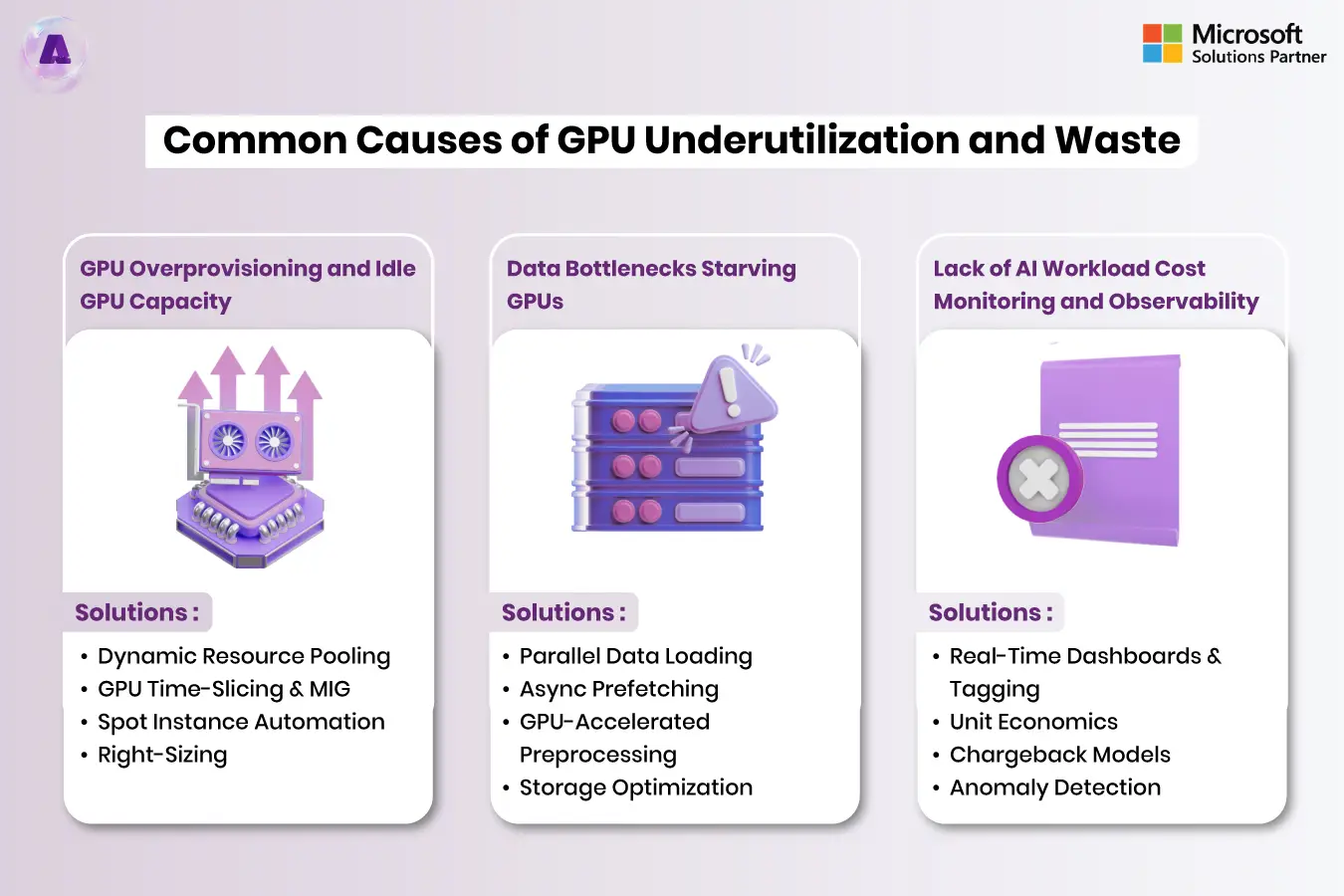
1. GPU Overprovisioning and Idle GPU Capacity
One of the most pervasive issues is provisioning more GPU capacity than workloads actually need. This often happens because teams:
- Use the same GPU shape for both training and inference
- Allocate a full physical GPU to small models that would comfortably run on a fractional share
- Keep clusters up “just in case,” leading to sustained GPU underutilization and high idle GPU costs
Several cloud and consulting case studies on GPU cost optimization for AI workloads report 25–40% cost reductions by addressing GPU overprovisioning with right-sizing and better scheduling.
Solutions:
- Dynamic Resource Pooling – Centralized GPU pool with intelligent scheduling replaces static per-project allocation, eliminating artificial scarcity
- GPU Time-Slicing & MIG – Multiple users share single GPU; H100 serves 8 simultaneous users with 75% per-user cost reduction
- Spot Instance Automation – Preemptible instances for experiments and batch training: 50-70% cost savings
- Right-Sizing – Separate GPU types for training vs inference workloads
Case Study/Real Example: Facial Recognition Company
A world leader in facial recognition technology operated 24 DGX servers across 30 researches but achieved only 28% GPU utilization. Static per-project allocation fragmented capacity, creating artificial bottlenecks while GPUs sat idle.
Implementing dynamic pooling with hardware abstraction enabled the system to allocate GPUs based on real-time demand rather than static reservations. Results: GPU utilization jumped to 73% (+161%), training speed doubled, the planned $1 Million hardware investment was avoided entirely, and teams ran 2x more experiments on the same hardware.
2. Data Bottlenecks Starving GPUs
Another form of waste occurs the time that GPUs remain idle and just waiting to receive data. Poorly designed data pipelines for data, slow storage of objects or the lack of a local location could result in lower GPU utilization, despite the fact that it has a high theoretical capacity for computation. This affects both AI workload efficiency and accuracy since training could be delayed or interrupted.
Solutions:
- Parallel Data Loading – Multi-worker preprocessing (8-16 workers) using PyTorch DataLoader or TensorFlow tf.data; hide data loading latency behind computation.
- Async Prefetching – Load batch N+1 while GPU processes batch N; +15-25% utilization gain.
- GPU-Accelerated Preprocessing – NVIDIA DALI offloads image decoding/resizing to GPU, eliminating CPU bottleneck.
- Storage Optimization – High-bandwidth storage (NVMe SSD, high-IOPS object storage) for 10+ GB/s sustained throughput.
Case Study/Real Example: Video Analytics for Precision Agriculture
A video analytics pipeline processing farm footage had three sequential stages: detected (8.8ms) + inference (6.9ms) + post-processing (40.2ms) = 55.8ms per frame. GPU sat idle while CPU processed results.
The team implemented batched GPU inference (8-16 frames per batch), vectorized distance computations, and parallel clustering. Results: 55.8ms → 26.3ms per frame (2.1x speedup), post-processing latency down by 72%, infrastructure cost reduced 55% ($0.69 → $0.31/run).
3. Lack of AI Workload Cost Monitoring and Observability
Without robust AI workload monitoring and GPU cost observability, it is nearly impossible to identify where waste occurs. Many organizations only discover their AI cost problems when monthly bills suddenly spike, leaving little time to respond.
The State of FinOps 2025 report highlights the fact that as AI usage increases the engineering and finance teams need to improve their cooperation and transparency, particularly for new AI-heavy tasks/workloads. This is precisely where FinOps for AI workloads comes in.
Solutions:
- Real-Time Dashboards & Tagging – Cost allocation by team, model, project, workload type; per-model cost visibility enables targeting.
- Unit Economics – Track cost per model retrain, per inference, per business outcome; discipline spending around value.
- Chargeback Models – Allocate costs to business units; monthly reviews, budget caps, and approval workflows change team behavior.
- Anomaly Detection – ML-powered alerts for spending spikes; reduce detection time from days to hours.
Case Study/Real Example: Global Bank – Fraud Detection
A bank with rapidly rising GPU costs found dev/test clusters running 24/7 and all experiments on expensive on-demand instances – with zero cost visibility. Implementing FinOps framework like cost tagging, real-time dashboards, chargeback plus operational fixes like automated off-peakcluster shutdown, spot instance migration for experiments delivered: 30% cost reduction, 40% more models deployed on lower spend, idle cluster hours fell from 60-70% to <20%, ROI per fraud prevention improved 15%.
Core Strategies for AI Workload Cost Optimization
1. Right-Sizing GPU Resources for AI
How to right-size GPU resources for AI is a foundational question in any AI workload cost optimization framework. Right-sizing includes:
- Assigning high-end GPUs to true training workloads only
- Using more cost-effective GPUs or even CPUs for lightweight inference workloads
- Exploring MIG (Multi-Instance GPU) utilization, which allows partitioning large GPUs into multiple isolated instances to eliminate waste for smaller models
WeTransCloud’s GPU cost optimization for AI workloads analysis shows that enterprises can often realize 30–40% savings by combining right-sizing, MIG, and instance family selection.
2. AI Workload Autoscaling and Dynamic Capacity Management
Static capacity planning almost guarantees waste. Instead, organizations should:
- Implement AI workload autoscaling policies based on real utilization and queue depth
- Utilize spot/preemptible instances for non-critical or resilient training workloads
- Tune GPU scheduling strategies to align resource allocation with workload patterns (e.g., Ray/Spark GPU scheduling for distributed inference and training)
This approach directly supports AI workload cost management by ensuring that capacity scales with demand rather than being overprovisioned “just in case.”
3. Cost-Aware MLOps and Pipeline Design
Cost-aware MLOps integrates resource and cost considerations into the end-to-end ML lifecycle. This includes:
• Instrumenting training and inference pipelines with cost metrics by model, team, and environment
• Surfacing those metrics in FinOps dashboards so teams see the cost impact of their design decisions
• Building guardrails (such as maximum cluster sizes or per-job budgets) into CI/CD workflows for models
Artech Digital’s discussion of AI cost optimization strategies emphasizes that organizations using structured FinOps practices can cut AI cloud costs by 20–50% while sustaining throughput. This directly supports AI workload spend control across the portfolio.
Conclusion: The Time to Modernize Is Now
AI workloads will only grow in importance and volume. Without intentional AI workload cost optimization strategies for enterprises, even the most impressive AI capabilities can become financially unsustainable. The combination of GPU cost optimization, AI compute cost optimization, cost-aware MLOps, and FinOps for AI workloads allows you to avoid GPU waste, control spend and reinvest savings into higher-value innovation.
The organizations that win in AI will not simply be the ones with the biggest models or the most GPUs—they will be the ones that can deliver reliable, performant AI at a cost that makes sense for the business.
If your company is determined to reduce AI workload scaling costs and eliminating the idle GPU costs, the next step is to conduct a thorough review of your current infrastructure, workloads and processes, followed by an optimized program that is based on the practices outlined above.
Frequently Asked Questions (FAQs)
- How to optimize AI workload costs without hurting performance?
Start by profiling existing workloads, then combine infrastructure right-sizing, GPU utilization optimization, AI workload autoscaling, and model-level techniques like mixed precision training and model right-sizing. These changes often improve performance while reducing cost.
- How to reduce GPU costs for AI workloads in the cloud?
Make use of fractional or smaller GPUs to infer and reserve the top GPUs for real-time training Utilize preemptible/spot instances whenever is possible, and use algorithms for scheduling GPUs in your GPU scheduling strategies to ensure that resources are not used up. Continuous AI workload cost monitoring is vital to maintain the progress.
- Why are AI workloads so expensive compared to traditional apps?
AI workloads rely on specialized accelerators, move large volumes of data, and often run continuously for training and inference. Without AI workload cost management, this can lead to GPU overprovisioning, idle GPU capacity, and opaque spending patterns that significantly exceed traditional application costs.
- What are common causes of GPU underutilization in AI projects?
Common reasons include the use of unnecessarily massive GPUs, using incorrect instance types for inference workloads, weak data pipelines that eat up GPUs, insufficient coordination of scheduling, and inability to observe into use. This is the most important step to reducing GPU waste.
- What infrastructure do I need for AI workloads?
Infrastructure requirements for AI workloads include GPU/TPU clusters, high-speed interconnects (InfiniBand/RoCE), NVMe storage, auto-scaling cloud platforms, data pipelines, and MLOps tools. Hybrid architectures are now standard.
- How can enterprises control AI compute spend at scale?
Enterprises can manage their spending by setting up FinOps for AI workloads and enforcing cost tag and allocation and integrating cost metrics into tooling for MLOps as well as setting alerts and budgets and constantly reviewing opportunities for optimization. This makes AI workload cost optimization into an ongoing process rather than a once-off initiative.
Table of content
- TL; DR:
- Introduction: Why AI Workload Cost Optimization Should be a Board-Level Priority
- In this guide, you will learn:
- Why the Urgency?
- What Makes AI Workloads So Expensive?




