

Introduction
AI POC to production is where most projects fail. MIT report shows that only 5% of GenAI pilots reach production, while over 85% of ML projects never make it past experimentation. This gap between AI POC to production exists because enterprise AI implementation is far more than model accuracy. It involves infrastructure, governance, integration, and long-term maintenance. Many teams underestimate these AI deployment challenges, leading to stalled initiatives and wasted budgets.
If you design early with production constraints in mind, your chances of success increase significantly. AI doesn’t fail in production—systems around it do.
In this guide, you’ll learn how to move from AI POC to production successfully using proven frameworks and best practices.
What Is an AI POC and Why Does It Matter?
An AI proof of concept is a small-scale experiment designed to validate whether a model can solve a specific business problem. Its job is not to build a finished product, but to test whether a particular AI approach can deliver value before you commit significant resources.
There are three distinct stages in the AI lifecycle management for AI POC to Production:
- POC tests the idea.
- Pilot validates the idea in a semi-real environment with a limited user group.
- Production deploys the system at full scale, serves real users, and operates under real business and regulatory constraints.
Each stage has different goals, different success metrics, and different infrastructure requirements.
POCs are valuable because they:
- Reduce risk and validate ROI early.
- Expose hidden issues in data pipelines, feature engineering, and system integration.
However, a POC is not production-ready AI. The transition requires a structured AI implementation framework and careful planning.
Key Differences: POC vs Production AI
Before moving forward, you need to understand how production AI differs from experimental setups.
| Dimension | POC | Production |
|---|---|---|
| Data | Clean, static | Messy, real-time |
| Environment | Local / Jupyter notebooks | Cloud or containerized |
| Workflow | Manual | Automated AI DevOps pipeline |
| Metrics | Accuracy | Reliability, latency, scalability |
| Governance | Minimal | Full compliance and audit |
| Team | Data Scientists | Cross-functional teams |
A POC optimizes for experimentation, while production systems prioritize reliability and scale. If you don’t align your POC metrics with production expectations early, you will face setbacks later.
Why AI POCs Fail in Enterprises and How to Fix Them?
Most failures are predictable. Understanding them helps you avoid repeating the same mistakes.
Lack of Business Alignment
Many projects start without clear ROI. Without measurable outcomes, executive support fades quickly.
Fix: Define success KPIs and business impact before your data scientists write the first line of code.
Data Quality Gaps
POCs often use curated datasets. Production systems deal with noisy, incomplete, and inconsistent data.
Fix: Run a comprehensive data readiness audit before the POC begins to identify potential silos or quality issues.
Infrastructure Unreadiness
Running a model on a high-end laptop is different from serving it to a global audience. An inadequate AI infrastructure for production leads to high costs and slow response times.
Fix: Test your infrastructure assumptions during the POC phase rather than waiting for the final launch.
No AI Lifecycle Management
Many organizations treat AI as a project rather than a product. When the POC ends, there is no roadmap for retraining, monitoring, or version management.
Fix: Build a living AI lifecycle roadmap from day zero, covering data updates, model refreshes, drift response, and governance checkpoints.
Absence of MLOps for Enterprises
Without MLOps for enterprises, there is no way to manage the AI POC to Production process efficiently. Models become orphans that no one knows how to update or retrain.
Fix: Introduce MLOps tooling and automated pipelines in parallel with your model development.
Talent and Skills Mismatch
Data scientists build models. ML engineers operationalize them. MLOps engineers automate and govern the full pipeline. These are three distinct roles, and collapsing them onto one person creates bottlenecks and quality gaps.
Fix: Staff cross-functional teams from the start, not after the POC completes.
Underestimation of Integration Complexity
Legacy ERP systems, fragmented data silos, and API compatibility issues can add months to a deployment timeline that looked simple on paper.
Fix: Map every system integration point before committing to an architecture.
Missing Scalable Architecture
A Python script that works for 10 requests per minute is not the same as a microservice that handles 10,000. The gap between prototype code and production-grade services is substantial.
Fix: Design for modularity and API-first from the prototype stage so enterprise AI scaling is an engineering task, not a rewrite.
A Step-by-Step Framework: Moving from AI POC to Production
This eight-step framework gives you a structured path from a validated POC to a production-grade AI system.
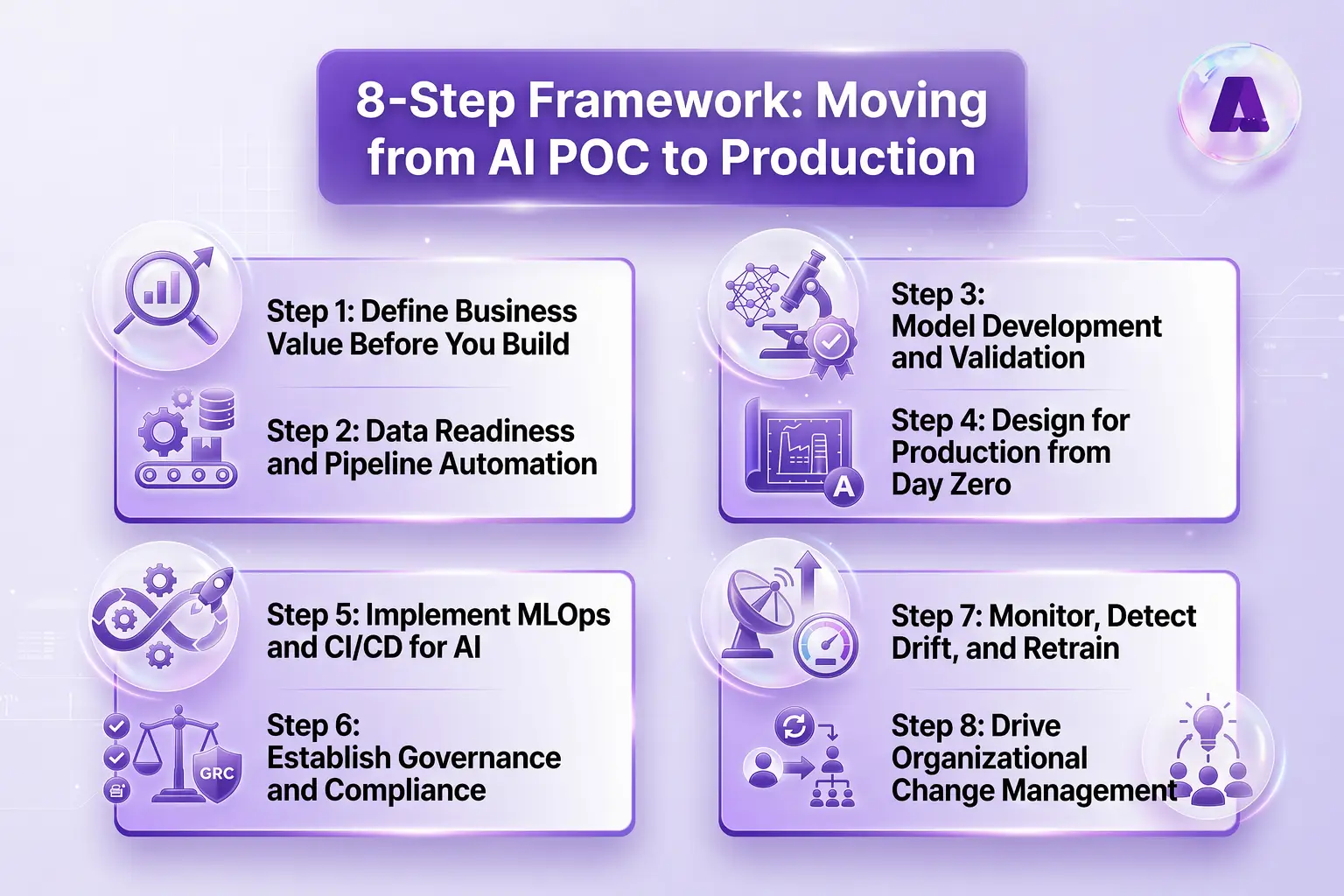
Step 1: Define Business Value Before You Build
Before writing a single line of model code, define 3-5 measurable production KPIs such as latency thresholds, accuracy floors, and uptime SLAs.
- What decision does this model support?
- Who uses the output?
- What does success look like at 10x the current volume?
Tie every technical choice to a specific business problem.
Step 2: Data Readiness and Pipeline Automation
Clean, governed data is the non-negotiable foundation for productionizing machine learning models. You need to automate your data pipelines to ensure a steady flow of quality information.
Version your datasets the same way you version code.
Step 3: Model Development and Validation
Production model development goes beyond maximizing accuracy on a test split. Robust cross-validation, bias detection, and fairness checks are standard steps. The evaluation criteria should mirror what production success actually looks like, including performance on out-of-distribution data and edge cases that your curated POC dataset never contained.
Always test model performance on data that mirrors production distribution, not just your cleanest training split.
Step 4: Design for Production from Day Zero
Production systems are built around modular, decoupled architectures exposed through well-documented APIs. So, containerization using Docker and Kubernetes is essential for maintaining consistency across environments.
Expose your model via a versioned REST or gRPC API from the start. It forces clean abstraction and makes future model swaps straightforward.
Step 5: Implement MLOps and CI/CD for AI
MLOps is what turns a deployed model into a managed system. It standardizes the training, validation, deployment, and monitoring pipeline so that updates are automated and governed. A mature MLOps setup includes:
- Continuous integration (testing code, data, and model changes)
- Continuous deployment (automated rollouts through staging and production environments)
- Continuous training (scheduled or triggered retraining when data drifts or performance degrades)
A model registry tracks what is running in production and when it was last updated. So, treat your ML pipeline like software. Every model change should trigger an automated test suite before it touches production.
Step 6: Establish Governance and Compliance
Role-based access control, audit trails, and model explainability documentation need to be built into the pipeline from the start. Regulated industries such as healthcare, finance, government face specific requirements under GDPR, HIPAA, and the EU AI Act. Data privacy protections, model versioning and lineage tracking, and bias detection are not optional features in these contexts.
Hence, bake compliance into the pipeline as a continuous automated gate at every stage, not as a final review before go-live.
Step 7: Monitor, Detect Drift, and Retrain
Once a model is live, its performance will eventually degrade. You need observability tools to detect model drift and concept drift in real time.
Set automated drift alerts with defined thresholds. Do not wait for users to complain about poor results.
Step 8: Drive Organizational Change Management
Cross-functional collaboration between data scientists, ML engineers, domain experts, and business stakeholders needs to be structured and sustained. Resistance to AI adoption is addressed through transparency, training, and meaningful feedback loops.
Involve domain experts and end users in model validation. Their feedback catches real-world failure modes that no benchmark will surface.
How to Build a Scalable AI Infrastructure for Production?
Building a robust enterprise AI architecture requires a layered approach. You cannot rely on a single monolithic script to handle everything from ingestion to inference. Most production-ready AI deployments use a five-layer stack.
- Data Ingestion Layer handles streaming and batch inputs from databases, APIs, sensors, and external partners. This layer includes schema validation, deduplication, and routing logic.
- Feature Engineering Layer applies consistent transformations to raw data, maintains a feature store for training and serving consistency, and manages feature versioning.
- Model Training Layer orchestrates compute resources, manages experiment tracking, and produces versioned model artifacts registered in a central model registry.
- Model Serving Layer handles both batch and real-time inference paths, routes traffic across model versions, and manages latency SLAs per endpoint.
- Model Monitoring and Governance Layer tracks data drift, model performance, system health, access logs, and compliance signals in a unified observability dashboard.
AI Model Deployment Best Practices
Here are a few practices to be followed for scaling AI POC to production:
Handling Inference Latency
Inference latency can ruin a user experience.
- Use model quantization, pruning, and knowledge distillation to reduce model size and inference time without proportional accuracy loss.
- Cache frequent predictions and route non-critical requests through asynchronous inference paths to cut tail latency significantly.
- Always profile under production load.
Distributed Systems and GPU Optimization
Multi-node training and distributed inference architectures are necessary for large models at scale.
- Right-size compute to run faster on CPU clusters than on expensive GPU instances at inference time.
- Do not default to GPU for serving without profiling first.
Scaling RAG in Production
For LLM applications using RAG (Retrieval-Augmented Generation) at scale, vector store selection and indexing strategy directly affect query latency and retrieval accuracy. Chunking strategy, embedding pipeline automation, and index maintenance all need to be production-grade.
- Cache frequent RAG queries and pre-compute embeddings for static knowledge bases to reduce RAG latency by 60–80% in practice.
Cost Optimization at Scale
AI infrastructure costs can grow linearly or faster with usage if not managed deliberately.
- Spot and preemptible instances work well for training workloads.
- Model compression reduces serving costs per request.
- Setting budget alerts and cost-per-inference targets early prevents the billing surprises that frequently emerge when LLM API usage scales.
Security Practices
Secure model endpoints require API key management, OAuth or mutual TLS (mTLS) authentication, and input validation to guard against adversarial inputs.
- Rate-limit every public-facing inference endpoint
- Authenticate every request and log for audit purposes
LLM Optimization
- Prompt versioning and regression testing catch silent degradation when prompts evolve.
- Output guardrails and content filters prevent harmful or off-policy responses from reaching users.
- Always build a deterministic fallback for LLM-powered features.
- LLMOps extends the MLOps lifecycle to cover prompt management, output evaluation, and hallucination monitoring.
Scaling AI requires optimizing performance, cost, and reliability simultaneously.
How to Build an MLOps Pipeline for Enterprise AI?
An MLOps pipeline is the automated backbone of your AI production system. It covers every stage from data versioning through model training, validation, deployment, monitoring, and retraining.
The core stages in order:
- Data versioning: track dataset versions alongside model versions so experiments are reproducible.
- Model training: automated, parameterized training runs triggered by new data or scheduled cycles.
- Validation: automated tests for model quality, bias, and regression against production benchmarks before any deployment.
- Deployment: staged rollouts through development, staging, and production with automated rollback triggers.
- Monitoring: continuous tracking of data drift, model performance, and system health.
- Retraining: triggered automatically when monitoring detects degradation or on a defined schedule.
Integrating MLOps into existing DevOps workflows is what makes AI operationally sustainable.
MLOps Tools and Platforms to Accelerate AI Production Deployment
Choosing the right stack is vital for moving your AI POC to production. You don’t have to build everything from scratch; many tools can help you automate the heavy lifting.
| Category | Tools |
|---|---|
| Experiment Tracking and Model Registry | MLflow, Weights and Biases |
| Orchestration and Pipelines | Kubeflow, Apache Airflow |
| Cloud MLOps Platforms | AWS SageMaker, Azure ML, Google Vertex AI |
| Monitoring and Drift Detection | Evidently AI, Deepchecks, Prometheus |
| CI/CD Integration | GitHub Actions, Jenkins, ArgoCD |
| Feature Stores | Feast, Tecton |
| LLMOps | LangSmith, Weights and Biases Prompts |
| Enterprise Deployment Partner | Aptly Tech |
Common AI Production Deployment Challenges — and How to Solve Them
AI deployment challenges are predictable for AI POC to Production. That means they are also preventable when you know what to look for.
| Challenge | Root Cause | Solution |
|---|---|---|
| Legacy system integration | Tightly coupled architecture | API abstraction layers and adapters |
| Cost overruns | Unoptimized compute | Dynamic scaling and model compression |
| Talent gaps | POC-to-prod skill mismatch | POC-to-prod skill mismatch |
| Security risks | No input validation or access control | RBAC, encryption, shift-left security |
| Model degradation | Unmonitored drift | Automated drift detection with retraining |
| Governance failures | No model lineage or audit trail | Model registries and compliance pipelines |
| Stakeholder resistance | Poor change management | Training, feedback loops, and transparency |
Enterprise Checklist for AI Production Readiness
Before declaring your AI system production-ready, work through this checklist. Each item represents a common failure point in enterprise AI deployments.
Strategy and Business Alignment
- Business value clearly defined with measurable KPIs
- Executive sponsorship and stakeholder buy-in secured
- ROI baseline and success metrics documented
Data and Pipelines
- Data pipelines automated and governed
- Datasets versioned and lineage tracked
- Feature store implemented for training and serving consistency
Infrastructure and Architecture
- Scalable, containerized infrastructure in place
- Inference endpoints load-tested under production conditions
- Cloud, hybrid, or edge strategy defined
MLOps and Deployment
- CI/CD pipelines configured for models
- Model versioning and registry established
- Automated retraining pipeline in place
Monitoring and Observability
- Monitoring, alerting, and drift detection active
- Observability dashboards built for model and data health
- Fallback mechanisms defined for model failure scenarios
Governance and Security
- Governance policies, audit trails, and RBAC implemented
- Security and compliance validated against GDPR, HIPAA, and EU AI Act requirements
- Model explainability documented for regulated use cases
People and Process
- Cross-functional team aligned and trained
- Change management plan in place
- End users involved in validation and feedback cycles
Conclusion
AI success is not about building better models—it is about building better systems around them. Organizations that treat AI as infrastructure, not experimentation, are the ones that successfully move from AI POC to production.
With the right combination of scalable architecture, MLOps, and governance, AI can evolve from isolated experiments into a reliable enterprise capability.
Ready to scale? Assess your readiness and talk to the experts at Aptly Tech today.
FAQs
Q: How do you move from AI POC to production?
You move from AI POC to production by shifting focus from experimentation to reliability. Start by defining business KPIs, then build robust data pipelines and production-grade infrastructure. Introduce MLOps for automation, implement CI/CD for AI, and deploy models via APIs. Finally, monitor performance and retrain models continuously to maintain accuracy.
Q: Why do most AI projects fail before production?
Most AI projects fail due to poor business alignment, weak data quality, and lack of scalable infrastructure. Teams often treat POCs as isolated experiments without planning for integration, governance, or lifecycle management. The absence of MLOps and cross-functional collaboration also contributes to failure.
Q: What is needed to deploy AI models at scale?
To deploy AI models at scale, you need reliable data pipelines, containerized infrastructure, automated CI/CD pipelines, and strong monitoring systems. You also need governance frameworks, model versioning, and optimized inference systems to handle high traffic and low latency requirements.
Q: How do enterprises operationalize AI?
Enterprises perform model operationalization by integrating models into business workflows and systems. This involves building MLOps pipelines, aligning teams across engineering and business functions, and implementing continuous monitoring. AI becomes part of daily operations rather than a standalone project.
Q: How to build MLOps pipeline for enterprise AI?
Start with versioning for data, code, and models. Build automated pipelines for training and validation. Integrate CI/CD for deployment and include monitoring tools for performance tracking. Over time, evolve toward full automation with continuous training and governance controls.
Q: How to scale AI models securely?
Secure AI systems by protecting APIs with authentication and encryption. Use role-based access control and validate all inputs to prevent attacks. Monitor system behavior and log activity for auditing. Security should be integrated into every stage of the pipeline.
Q: What is required to move AI into production?
Organizations need scalable infrastructure, MLOps pipelines, governance frameworks, and cross-functional alignment to successfully deploy AI systems.
Q: What are the top platforms for deploying AI models from POC stage?
Popular platforms include AWS SageMaker, Azure Machine Learning, and Google Vertex AI. These platforms provide end-to-end capabilities for training, deployment, monitoring, and scaling AI models in enterprises. Leveraging AI production deployment partner like Aptly Tech will help you easily move AI POC to Production.
Table of content
- TL;DR
- Introduction
- What Is an AI POC and Why Does It Matter?
- Key Differences: POC vs Production AI
- Why AI POCs Fail in Enterprises and How to Fix Them?
- A Step-by-Step Framework: Moving from AI POC to Production
- How to Build a Scalable AI Infrastructure for Production?
- AI Model Deployment Best Practices
- How to Build an MLOps Pipeline for Enterprise AI?
- MLOps Tools and Platforms to Accelerate AI Production Deployment
- Common AI Production Deployment Challenges — and How to Solve Them
- Enterprise Checklist for AI Production Readiness
- Conclusion
- FAQs




